Occasionally, not thinking about things allows some room in the mind to think.
I’ve spent weeks reading and rereading these Seroquel Clinical Trials and remained befuddled. The graphs all look almost the same. I even named them after the Companies that make them [Clinical Research Organizations]:
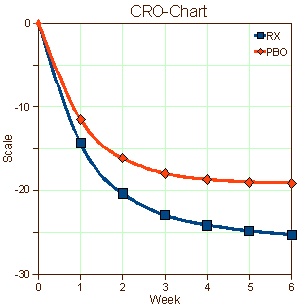
The most obvious problem is that the Placebo subjects improve dramatically in many of the trials. When I go looking for how to explain that, the answers aren’t very satisfying. Since there’s a big drop-out rate [50%+], maybe it’s because the people on placebos that are getting worse drop out. But in the studies with more available data, that’s not always the case. And that’s not all of what’s wrong with these graphs – the differences generated may be statistically significant, but they often look kind of trivial.
Earlier [seroquel II [version 2.0]: guessing…], there was an example that has stayed with me [Trial 0006]. This was the graph published in the study itself, a CRO-Chart extraordinare:
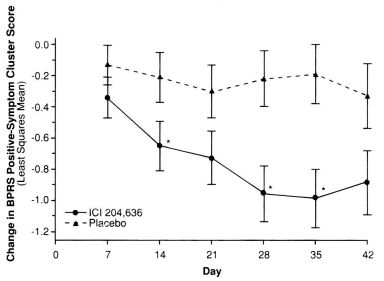
But in the F.D.A. approval documents, they had the information from before the LOCF [Last Observation Brought Forward] correction was applied, so we got closer to what they actually observed – the mean scores of the non-drop-outs (BPRS [PSS][OC]) uncorrected:
In the published paper, the authors concluded:
In this placebo-controlled, multicenter trial, ICI 204,636 was effective in the treatment of the positive and negative symptoms of schizophrenia. Significant differences (p less or equal to 0.05) between treatment groups were identified for the primary efficacy variables, the BPRS total score and CGI Severity of Illness item score, at most times throughout the trial, with marginal significance achieved at endpoint (p = 0.07 for both)…
Looking at the Observed Cases, I think that’s a totally unsupportable conclusion at best. And in the F.D.A. Report, they give us the the Mean scores of the drop-outs at the time they dropped out:
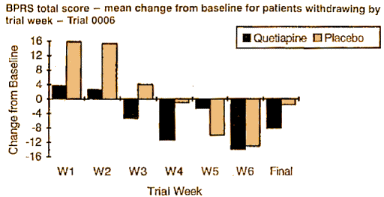
Even with this additional information, we can’t reconstruct the primary data-set. What we can see is that the profiles of the scores of the drop-outs between the Placebo and Quetiapine are dramatically different [but the number of drop-outs at each week is missing]. Those aren’t "random drop-outs."
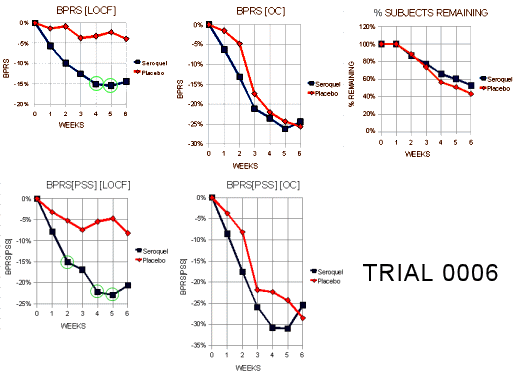
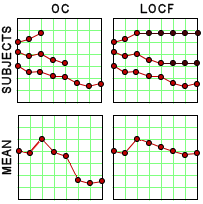 Since I’d never heard of this Last Observation Carried Forward business, I wrote a more savvy friend about it. He explained that it was a way to fill in for missing data. Since there are a lot of drop-outs in these Clinical Trials, they take the Last Observed value at the time of drop-out and pretend it’s the value for the remaining periods in the study [see the graph on the right]. Obviously the graphs of the means using Observed Case Values and Last Observation Carried Forward values are remarkably different. In reading about this method, they talk about two kinds of drop-outs: non-informative [random] and informative [having to do with the variables measured]. Examples of the latter would be things like clinical worsening, drug side effects, etc. The LOCF method is recommended for data with non-informative drop-outs [which is not necessarily the case in these studies]. What it comes down to is that this is just a convention in Clinical Trials. There’s another more complex model MMRM [Mixed-Effect Model Repeated Measure] that is increasingly recommended. Here’s how people at the F.D.A. talk about the difference between the two methods:
Since I’d never heard of this Last Observation Carried Forward business, I wrote a more savvy friend about it. He explained that it was a way to fill in for missing data. Since there are a lot of drop-outs in these Clinical Trials, they take the Last Observed value at the time of drop-out and pretend it’s the value for the remaining periods in the study [see the graph on the right]. Obviously the graphs of the means using Observed Case Values and Last Observation Carried Forward values are remarkably different. In reading about this method, they talk about two kinds of drop-outs: non-informative [random] and informative [having to do with the variables measured]. Examples of the latter would be things like clinical worsening, drug side effects, etc. The LOCF method is recommended for data with non-informative drop-outs [which is not necessarily the case in these studies]. What it comes down to is that this is just a convention in Clinical Trials. There’s another more complex model MMRM [Mixed-Effect Model Repeated Measure] that is increasingly recommended. Here’s how people at the F.D.A. talk about the difference between the two methods:MMRM vs. LOCF: A Comprehensive Comparison Based on Simulation Study and 25 NDA Datasets
Journal of Biopharmaceutical Statistics 2009, 19:227 – 246
by Ohidul Siddiqui, H. M. James Hung, Robert O’Neill
AbstractIn recent years, the use of the last observation carried forward (LOCF) approach in imputing missing data in clinical trials has been greatly criticized, and several likelihood-based modeling approaches are proposed to analyze such incomplete data. One of the proposed likelihood-based methods is the Mixed-Effect Model Repeated Measure (MMRM) model. To compare the performance of LOCF and MMRM approaches in analyzing incomplete data, two extensive simulation studies are conducted, and the empirical bias and Type I error rates associated with estimators and tests of treatment effects under three missing data paradigms are evaluated. The simulation studies demonstrate that LOCF analysis can lead to substantial biases in estimators of treatment effects and can greatly inflate Type I error rates of the statistical tests, whereas MMRM analysis on the available data leads to estimators with comparatively small bias, and controls Type I error rates at a nominal level in the presence of missing completely at random (MCAR) or missing at random (MAR) and some possibility of missing not at random (MNAR) data. In a sensitivity analysis of 48 clinical trial datasets obtained from 25 New Drug Applications (NDA) submissions of neurological and psychiatric drug products, MMRM analysis appears to be a superior approach in controlling Type I error rates and minimizing biases, as compared to LOCF ANCOVA analysis. In the exploratory analyses of the datasets, no clear evidence of the presence of MNAR missingness is found.
I don’t understand all that I read in this abstract or the paper itself, but I do get the main point. The LOCF method is as shaky as it seems like it ought to be, and it produces Type I [false positive] errors and hides bias. In reading all of the published papers of Clinical Trials of Seroquel, I only found one that used the MMRM method to analyze the data.
So back to that empty mind thing. While I was watching the waves coming in at the beach last week, I realized something about why I spent 20 years practicing Psychiatry but largely ignored what was going on in the psychopharmacology world. I was intimidated by their scientific rhetoric. I thought they knew what they were talking about and I didn’t. So I didn’t learn how to separate the wheat from the chaff. I avoided the literature and relied on others to tell me about these new drugs [that I rarely used] because I felt the studies were beyond me [and terminally boring]. It didn’t occur to me that the opacity of the articles might be a deliberate trick. I hadn’t learned to look at who funded the study, who assisted with medical writing, where all those additional authors worked, to find out what the LOCF method was – that it’s fraught with errors. I assumed a scientific integrity where none existed. I’ll bet a lot of us did that – got scared off by the jargon – and didn’t apply a critical eye to the journals [or avoided them altogether]. That’s one of the things that popped into my empty mind at the beach.
A few posts back, I mentioned a vignette from 2004 [selling seroquel VII: indication sprawl…]. Dr. Nassir Ghaemi was asked to be a second author on one of those CRO-Chart articles comparing Seroquel and Haldol in Mania. He insisted on seeing the data from the study and actually in participating in writing the paper. AstraZeneca said "No." More than that, they felt that if they were forced to show him the data, he’d have to look at it in the company of their own scientists and statisticians. I had run across references to those emails before in an index, but I hadn’t read them:
Another empty mind at the beach thing… I’ve spent a couple months going from study to study, trying to figure out about the drop-out rates, trying to find a primary data set where I could see how all this LOCF business worked, and I can’t find one – not one. In my beach empty mind I thought, "The reason I can’t find any raw data is not because I’m an inadequate searcher, it’s because it’s not there – for a reason. They don’t want me to see it." Then I remembered the Ghaemi email, and when I got home to my real computer, I looked it up. They didn’t even want the paper’s author to see the raw data.
I ended my last post with, "Statistical significance in a CRO-Chart is simply not enough. That’s my take-home from reading the published versions of these Seroquel Clinical Trials. It has become a ‘time-to-market’ racket…" I know that to those of you who have been following this stuff for a long time, that might be something you’ve known forever. My problem is that I only "sort of" knew it – or only knew pieces of it. I knew Dr. Nemeroff at Emory was a self-serving opportunist. I knew that GSK had misbehaved with Paxil and AstraZeneca was overselling Seroquel. I didn’t miss the point that the F.D.A. fined Eli Lilly $1.4 B for something. But somehow, I hadn’t really clicked into understanding that the entire industry-funded Clinical Trials scene in Psychiatry is suspect. It really is a racket. It feels kind of paranoid to say that [just like it felt like saying that Sub-Prime Mortgages were a racket four or five years ago]. Before I launch an attempt to understand the CROs, I’d like to mention three articles I ran across in my wanderings. They are attached [abstracts and conclusions] for those who haven’t read them.
-
The first is Last-Observation-Carried-Forward Imputation Method in Clinical Efficacy Trials: Review of 352 Antidepressant Studies. The authors did a literature search of the Clinical Trials for the Antidepressants between 1965 and 2004. They demonstrate how these studies increasingly drifted towards using the LOCF methods without including the ancillary information that allow an accurate assessment of the results. They make it clear what information needs to be included in the articles [and it never is]. These authors already knew what it’s taken me months and a beach trip to figure out – in their current form, the Clinical Trials articles are deliberately opaque.
-
The next article is Why Olanzapine Beats Risperidone, Risperidone Beats Quetiapine, and Quetiapine Beats Olanzapine: An Exploratory Analysis of Head-to-Head Comparison Studies of Second-Generation Antipsychotics. In this article, the authors look at the industry supported head-to-head Clinical Trials and point out the obvious – the sponsor’s drug wins. But they go further and demonstrate the subtle ways that these studies are manipulated by the study design and writing methods to move the outcomes in the desired directions. It’s a must-read in full.
-
This final article is recent, sent to me by PharmaGossip, Those Who Have the Gold Make the Evidence: How the Pharmaceutical Industry Biases the Outcomes of Clinical Trials of Medications. While this is the most cynical article of the bunch, it’s the closest to the emerging truth:"We can reasonably ask that pharmaceutical companies not break the law in their pursuit of profits but anything beyond that is not realistic. There is no evidence that any measures that have been taken so far have stopped the biasing of clinical research and it’s not clear that they have even slowed down the process. What will be needed to curb and ultimately stop the bias is a paradigm change in the relationship between pharmaceutical companies and the conduct and reporting of clinical trials."
I think the CROs are the intelligence behind this whole game, the ghost in the machine, but since I’ve only known they exist for a month or so, I’ve got some catching up to do. It might require another beach trip…
Mickey — Way back when I was still occasionally prescribing an SSRT for a few patients, I was impressed with the results in one patient to Lexapro; so I began using that as my first choice. Mine was really a very small sample because I was seeing mostly psychoanalytic patients or others who didn’t need meds.
Then I noticed an ad placed by the Lexapro company itself in the APA Journal touting its effectiveness — and the ad included a graph that was almost identical to your CRO-Chart above. I kept it for years, as my justification for backing off using meds for relatively mild to moderate symptoms of anxiety and depression.
Why use something that — although it may have had a slight statistical improvement — most of the dramatic “improvement” was also there in the placebo group.
Me too. They fooled us all. The problem with those CRO-Charts is that they look the same for genuinely effective and barely effective drugs. They’re for the FDA, not clinicians. I’m working up a real resentment about how much we’ve been played in all of this…