931 of their 4041 subjects had not met their enrollment requirements [607 did not have HRSD scores high enough to qualify and 324 did not have HRSD scores administered]. 370 of the subjects were eliminated from the Level 1 calculation because they had no post-baseline visit. They had, however, been started on medication and by protocol should’ve been included.
The protocol defined the outcome measures as the HRSD [Hamilton Rating Scale for Depression] and the ISD [Inventory of Depressive Symptomatology], both Clinician Rated. Instead they used the QIDS [Quick Inventory of Depressive Symptomatology], a Self-Rated scale they had developed themselves – a scale that they had said was only going to be used for clinician decision making along the way [unblinded].
The Report presented the remission rates at the end of the year’s follow-up in an unintelligible manner. Although they reported a "theoretical" remission rate of 67%, only 108 subjects who stayed in the study actually had a sustained remission at one year.
Some of the reasons I think that STAR*D was presented in a deliberately misleading way have already been covered. They made all those protocol changes after the results were unblinded [a big no-no]. They specifically didn’t tell us that the 370 people they dropped had already been started on Level 1 treatment. They gave us a specific rationale for changing outcome measures in mid-stream which may or may not have contained some truth, but that rationale had a great big lie right in the middle of it. They presented the response, remission, and relapse data in a way that could not be deciphered, instead of showing it to us in a simple table [from Pigott]:
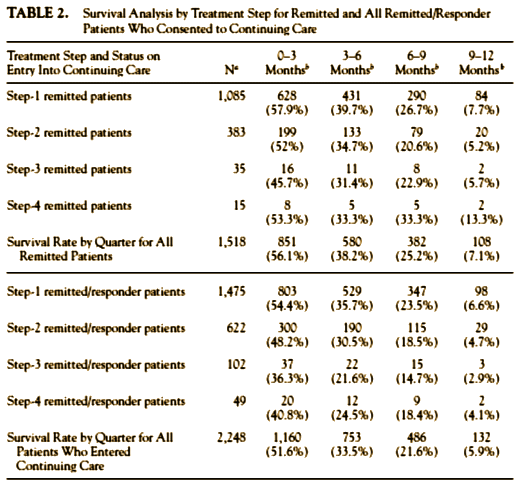
There was more, a lot more, in Pigott’s paper. That’s why I suggest you take a look at it on your own. Just a few pieces from the mound of evidence. Every infraction, every change, every omission, even down to how the rounded off their numbers, moves the results in the same direction – towards increasing the apparent efficacy of their antidepressant treatment. In spite of squeezing out some seventy published papers, they’ve never published the outcome data pre-defined by their protocol – the before and after HRSD or ISD scores at the different levels. He found evidence of bias in the American Journal of Psychiatry‘s handling of the study, and at the NIMH as well.
His answer is revealing for two reasons. First, he is acknowledging that the low remission and stay-well rates reported by the Pigott group are accurate. Those are indeed the real results. Second, he is acknowledging that the STAR*D investigators knew this all along, and that, in fact, this information was in their published reports. And in a sense, that is true. If you dug through all of the published articles, and spent weeks and months reading the text carefully and intently studying all the data charts, then maybe, at long last, you could — like Pigott’s group — ferret out the real results.
I hope you and Dr. Piggott take this a little further, and come up with some guidelines indicating when study results are likely to be bogus. For example, if the primary outcome measure is changed halfway through, or even worse, after the study is concluded, that’s a signal. If they make up their own outcome measure, that’s another. If you cannot follow what happened to the people enrolled in the study, that’s another. And a biggie–if the study looks like it’s been designed to support or align with something else that was discredited–in this case, TMAP–or those involved have conducted other discredited work.
That’s exactly right, but easier thought than taught. Dr. Pigott has done a fine job of finding the holes in this leaky bucket. We just need more people out there looking…
Hope you saw the posting today on Pharmalot regarding the link between SSRIs and breast cancer, as well as the impact of industry ties on which researchers were likely to acknowledge that link.
Dear B.O.M . , thanks enormously for this excellent and measured synthesis of Piggott and Whitaker’s critically important contributions in this area. I will be be directing colleagues and email list members worldwide to your blog as a brilliant resource for a succinct overview of this very important area, clinically and scientifically (and regarding public health policy). I hereafter cut’n’paste a comment i’ve posted to Whitaker’s Psychology Today blog about this area – with apologies and asking forgiveness for “cross-posting” and some element of laziness!
Vital information for Primary Care Docs, Psychiatrists, and Patients
I write to thank Robert Whitaker and especially Ed Piggott for the enormous work done in this critically important re-analysis of the STAR*D data, and for doing their utmost to let others know of the results. As a psychiatrist i daily see “colleagues” believing and slavishly following the hype, with polypharmacy, high doses, unending medication suggestions the norm.
Primary Care Docs do most of the prescribing here in Australia, as in the USA, and meds as first step for ANY emotional upset is such received wisdom that NOT doing so feels nearly malpractice, if you read the literature (increasingly marketing tools of pharma) uncritically. Honest appraisal of data such as Dr Piggott has provided need to be disseminated as widely, clearly and succinctly as possible.
Hence a request – to distill these very concerning findings to a quickly readable abstract, highlight key unarguable data points, make the 2.7% non-relapsing endpoint crystal clear – so that Primary Care Docs may see that their patients continuing to struggle ain’t their (or patients) fault, needing more meds, or needing more “aggerssive” Rx of some other kind.
Patients need to know they aren’t broken, their chemicals AREN’T imbalanced, that meds may help a bit but will likely NOT help enormously nor “fix” them, and that simple daily behavioral strategies (behavioral activation, mindfulness, which together make up my approach [disclosure] – Acceptance and Commitment
Therapy) can get them back to valued living, even with difficult thoughts and feelings arising from time to time.
Apologies for long comment. Hope of some interest / use. I will later comment about an alternative approach to human behavior and medications with a long and solid scientific history, functional contextual behavioral pharmacology, if readers/blog host interested.
With enormous gratitude,
Rob Purssey
Psychiatrist and ACT Therapist, Brisbane, Australia
http://www.mindfulpsychiatry.com.au