I’m still on STAR*D, and I put this first part in a box for two reasons – it’s convoluted, in spite of my attempts to make it clear. You might even skip it if you have an aversion to initials and technical talk. My second reason is so you can find it when you get to the end and decide you want to look it over again [or for the first time]:
|
In looking at the STAR*D study [recalculating…], there was a very confusing part about changing the primary out come measures along the way – from the standard HRSD [Hamilton Rating Scale for Depression] to the QIDS-SR [Quick Inventory of Depressive Symptomatology–Self-Report]. If you don’t remember it, you might want to look back at my post about it. It turned out that that change was never approved by the NIMH DSMB [Data Safety and Monitoring Board]. It turns out that this is not just some picky point, because this new outcome measure was not blinded during the study and available to the treating clinicians along the way. What made it worse, in the paper, the authors said, "the QIDS-SR was not used to make treatment decisions, which minimizes the potential for clinician bias." I claimed that was a lie. But looking back at the exact wording in the paper,
The clinical research coordinators also completed the 16-item, clinician-rated Quick Inventory of Depressive Symptomatology [QIDS-C16] at each clinic visit to assess symptoms over the prior week… Patients also completed the 16-item Quick Inventory of Depressive Symptomatology-Self-Report [QIDS-SR16] and the Frequency, Intensity, and Burden of Side Effects Rating at each clinic visit.
maybe they’ve got me on a technicality. The QIDS-C and the QIDS-SR are identical. Maybe they are trying to sell us that the clinician rated version was open, and the self-report was blinded. Since they’re identical and were done in the same visit, their statement is certainly not the truth. And then they used the QIDS-IVR [Quick Inventory of Depressive Symptomatology–Interactive Voice Response] which is a call-in telephone system version to follow subjects for a year to detect relapses. Here’s how they put it:
We used the Quick Inventory of Depressive Symptomatology–Self-Report (QIDS-SR) as the primary measure to define outcomes for acute and follow-up phases because:
2. QIDS-SR and HRSD outcomes are highly related
3. the QIDS-SR was not used to make treatment decisions, which minimizes the potential for clinician bias
4. the QIDS-SR scores obtained from the interactive voice response system, the main follow-up outcome measure, and the paper-and-pencil QIDS-SR16 are virtually interchangeable, which allows us to use a similar metric to summarize the acute and follow-up phase results.
Response was defined as at least a 50% reduction from treatment step entry in QIDS-SR16 score. Remission was defined as a QIDS-SR16 score ≤5 [corresponding to an HRSD17 score of ≤7]. Relapse was declared when the QIDS-SR16 score collected by the interactive voice response system during the followup phase was ≥11 [corresponding to an HRSD17 ≥14].
|
None of this makes one iota of sense. Why change from a tried and true standard like the HRSD [Hamilton Rating Scale for Depression] to the QIDS-SR [Quick Inventory of Depressive Symptomatology–Self-Report] which none of us have ever heard of? Why say that the change was approved by the NIMH DSMB when it wasn’t? Why would you count on a telephone call-in system as your main follow-up measure? It sure didn’t work – in fact it may have made the outcome virtually unusable:
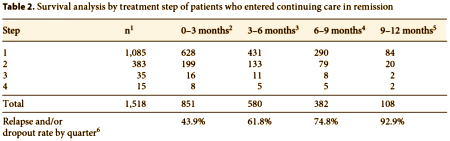
So far, we’ve got a confusing box and an inconclusive table. It seems only fitting to follow that up with unprovable suspicions.
The QIDS-SR was introduced in 2003 by Rush, Trivedi, et al [accepted for publication Nov 2002]. There are nine articles in PubMed with "QIDS" in the title [six from their group], all validating the scale. So it seems to have been developed for or around the time of STAR*D. I can only find one study comparing the QIDS-C, QID-SR, QID-IVR, and the HRSD — written by the STAR*D group and published a few months before the STAR*D report in 2006. The correlation looks okay to me:
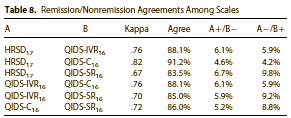
When I was looking over Dr. Pigott’s studies, he and I had some correspondence, and among the things he sent was a piece of his sleuthing he didn’t publish because it was conjecture. I thought it was worth saying and with his permission, I’ll add it here.
The 30 item Inventory of Depressive Symptomatology (IDS) (Rush et al. 1986, 1996) and the 16 item Quick Inventory of Depressive Symptomatology (QIDS) (Rush et al. 2003) are designed to assess the severity of depressive symptoms. Both the IDS and the QIDS are available in the clinician (IDS-C30 and QIDS-C16) and self-rated versions (IDS-SR30 and QIDS-SR16). The IDS and QIDS assess all the criterion symptom domains designated by the American Psychiatry Association Diagnostic and Statistical Manual of Mental Disorders – 4th edition (DSM-IV) (APA 1994) to diagnose a major depressive episode…
Current translations of the pencil and paper versions of the IDS and QIDS are available at no cost to clinicians and researchers. Copies may be downloaded from this site and used without permission. The IDS and QIDS are available in an automated telephone-administered format (IVR) exclusively licensed to Health Technology Systems. Those wishing to consider the IVR versions or other electronic versions should contact: Healthcare Technology Systems, Inc.
I guess I can see why Dr. Pigott didn’t include any of this in his publications or communications. It’s all suggestive but circumstantial, and he’s being careful not to say anything he can’t prove. I started to pass over it myself, but then I thought about what conflict of interest is really supposed to mean – anything that gives the appearance of bias. The standards for a scientist or a physician are different than they are in criminal court, at least they ought to be.
They apparently decided to use the QIDS as the primary outcome measure late in the game. The definitive study comparing the QIDS-C, QID-SR, QID-IVR, and the HRSD wasn’t even done until the STAR*D data was available. How do we know that other than its publication date being only a few months before the study itself? We know it because the study data itself was used to derive those correlations shown above.
In the annals of clinical trials for depression there is no precedent for relying on patients’ self report as the primary outcome measure. Yet that is what NIMH allowed to happen here with STAR*D when they decided to run with the QIDS-SR16. What were they thinking – especially in a trial of this importance? I and others have long argued for more attention to patient self reports in clinical trials, but clinician rated measures remain essential.
Moreover, in at least one of the early publications that aims to make a case for the validity of the QIDS-SR16 instrument, the QIDS-SR16 scores were simply extracted from the longer IDS-SR30 ratings. In other words, the QIDS-SR16 was not evaluated as an independent instrument. This sort of short-cutting sends shivers down the back of any self respecting psychometrician. [See MH Trivedi et al Psychological Medicine 2004; 34: 73-82.]
On March 1, 2011, the Texas Department of State Health Services (DSHS) replaced TIMA with the DSHS Psychotropic Treatment Recommendations. The new recommendations included “…Stop requiring rating scales for the psychotropic treatment recommendations. These scales will remain part of the Uniform Assessment…â€
DSHS also replaced the TMAP algorithms for MDD with APA’s guidelines. See
http://www.dshs.state.tx.us/mhsa/medicaldirector/
Thanks Nancy.
And as for the QIDS, they’re less enthusiastic on the Southwestern website [see Update]:
Mickey, I noted as well that the Southwesterners remain optimistic about the success rate of current treatments, according to their website: “Despite the recurrent nature of depression, depression is a highly treatable illness. The available therapeutic options are successful in 60-80% of all patients, so patients who receive treatment have a good chance of achieving remission.” See
http://www8.utsouthwestern.edu/utsw/cda/dept153397/files/169482.html