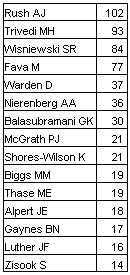
 Looking at all the STAR*D articles really gets one’s counting juices flowing. I wonder if any study has generated so many articles. I think I must’ve developed a case of number envy. There are 123 articles in PubMed with STAR*D in the title and and 204 with STAR*D in any field. Anyone who has looked at these articles is struck by the number of authors on each article and the fact that the names become monotonous. I started doing a PubMed search with name[AUTHOR] AND star*d which means search for all the articles with name in the AUTHOR field and "star*d" anywhere else. I just kept changing name using the authors that kept recurring. The double digit authors are listed on the right [my apologies if I missed anyone]. I’ve heard the term "résumé building" before and think about it every time I see a résumé like Nemeroff’s or Shatzberg’s with 400+ articles, but I think the STAR*D group takes the prize for doing it with a single study.
Looking at all the STAR*D articles really gets one’s counting juices flowing. I wonder if any study has generated so many articles. I think I must’ve developed a case of number envy. There are 123 articles in PubMed with STAR*D in the title and and 204 with STAR*D in any field. Anyone who has looked at these articles is struck by the number of authors on each article and the fact that the names become monotonous. I started doing a PubMed search with name[AUTHOR] AND star*d which means search for all the articles with name in the AUTHOR field and "star*d" anywhere else. I just kept changing name using the authors that kept recurring. The double digit authors are listed on the right [my apologies if I missed anyone]. I’ve heard the term "résumé building" before and think about it every time I see a résumé like Nemeroff’s or Shatzberg’s with 400+ articles, but I think the STAR*D group takes the prize for doing it with a single study.I got to wondering about production – how they could produce so many articles? So I did a time study on the four heaviest hitters [the darkened ones are "first author"]:
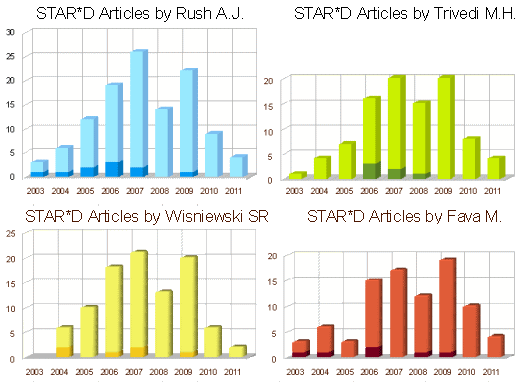
Looks like 2008 wasn’t a very good year, STAR*D production-wise. Senator Grassley was asking questions, naming names. He even named Dr Rush in his probe of Academics with unreported drug company income. TMAP in Texas was definitely on the skids. Rush left the Department in Dallas and moved to Singapore [not Singapore Texas]. But after an industry-wide STAR*D slow-down in 2008, they bounced back in 2009.
I hope by now you’ve figured out that this post is intended to be a parody on STAR*D. Just because there’s a PubMed Database of scientific articles that I know how to search, and just because I know how to use a spread-sheet and turn its tables into graphs, doesn’t mean that I have something to say. All I said in those first two paragraphs with it’s table and graphs is that the STAR*D people were churning their résumés and couldn’t possibly have written that many thoughtful articles in the given time frame. But you already knew that from my last post – they had full-time help. What I just did is how I think of all those article titles that stream past when you do the STAR*D searches – answering trivial questions that you probably already mostly knew the answers to before they wrote the papers.
-
"…In most of my own publishing history, the end product bore only a passing resemblance to the original draft. Why? Because the process of writing a scientific paper consists in interrogating the data ever more rigorously…"
-
" For some reason, I have this image of the spoils of each new article’s ‘authorship’ being divvied up amongst those in the pool via one of Rush/Trivedi’s ‘evidence-based algorithms’ that is essentially unrelated to the substance of the article itself…with then each article actually being written by Jon or some other ghost!"
-
"To paraphrase E.R. Murrow’s famous quote: “A nation of clerks begets mediocrity and wholesale decline.” (I’m also reminded of the symbol of the snake consuming itself from the back end.) Master Kilner and his colleague Sally may be paid shills but real accountability for what’s become of integrity in academic medicine or even American industrial competitiveness lies with the people who started out being doctors or gifted tinkerers and adopted the NYSE meme as their ‘raison d’être’."
-
And take a look at Nancy’s link to Dr. Rush’s slides on how to get published and arrange authorship hierarchies.
Sorry, the comment form is closed at this time.