 My Dad had been a ball player, but by the time I came along, he was a Coach – my uncle too. People on the street called them both ‘Coach’ and it sounded like ‘Doctor’ or ‘Mr. President’ and I felt proud. They had grown up poor. Sports were a way to escape working in the mines, so it had to be a consuming interest for it to succeed – and it was. I grew up with sports and the Stats as the most important things going. The first part of the newspaper my Dad read were the Box-Scores from last night’s games in whatever sport was in season, in preparation for the evening game on the radio. I remember when television came and you could actually see the game, it was different. I was used to seeing the game in fantasy with pictures from the baseball cards, sports page, and stats from the box scores all dancing in my head. Being able to actually see the game played took some getting used to.
My Dad had been a ball player, but by the time I came along, he was a Coach – my uncle too. People on the street called them both ‘Coach’ and it sounded like ‘Doctor’ or ‘Mr. President’ and I felt proud. They had grown up poor. Sports were a way to escape working in the mines, so it had to be a consuming interest for it to succeed – and it was. I grew up with sports and the Stats as the most important things going. The first part of the newspaper my Dad read were the Box-Scores from last night’s games in whatever sport was in season, in preparation for the evening game on the radio. I remember when television came and you could actually see the game, it was different. I was used to seeing the game in fantasy with pictures from the baseball cards, sports page, and stats from the box scores all dancing in my head. Being able to actually see the game played took some getting used to.
 There were live games too at the local park [Coach’s kids got in free]. In the stands, there were lots of people who scored the game on an elaborate form in the program. They kept up with every pitch, every hit, and drew pictures with special symbols of the play. They were the ones who knew their Stats and would predict things [like in the recent movie Moneyball]. It was like the players weren’t real people. They were Stats too – ERAs, RBIs, Steals. "He leads the league in whatever"
There were live games too at the local park [Coach’s kids got in free]. In the stands, there were lots of people who scored the game on an elaborate form in the program. They kept up with every pitch, every hit, and drew pictures with special symbols of the play. They were the ones who knew their Stats and would predict things [like in the recent movie Moneyball]. It was like the players weren’t real people. They were Stats too – ERAs, RBIs, Steals. "He leads the league in whatever"
When I got to Statistics in school, it was mostly about probability – how probable is it that something is significant, or is it just chance. I had to get used to that. In Baseball, everything had been significant. This was a different kind of Stats. Even in a Master’s program in Statistics back when, it was mostly about probability – a kind of yes-no science. With Baseball, there was so much more. That Babe Ruth or Shoeless Joe were probably going to get hits wasn’t enough. What kind of hit was the question. A double? a triple? a homer? an RBI? Could you count on them in a clinch? It was more than probability, it was effect size [how strong was Babe’s mojo?] and reliability [how often did Shoeless Joe get on base? steal?]. I’m just learning about those kinds of Stats in medicine – things like NNT [number needed to treat], OR [odds ratio], Effect Size, and Kappa. And Kappa is on the front burner right now since the DSM-5 Field Trials have been completed. Kappa is about reliability.
![Robert Spitzer [and the ghost of Emil Kraepelin]](http://1boringoldman.com/images/dsmiii-7.gif "Robert Spitzer [and the ghost of Emil Kraepelin]")
A Re-analysis of the Reliability of Psychiatric Diagnosis
By ROBERT L. SPITZER and JOSEPH L. FLEISS
British Journal of Psychiatry. 1974 125:341-347.
Classification systems such as diagnosis have two primary properties, reliability and validity. Reliability refers to the consistency with which subjects are classified; validity, to the utility of the system for its various purposes. In the case of psychiatric diagnosis, the purposes of the classification system are communication about clinical features, aetiology, course of illness, and treatment. A necessary constraint on the validity of a system is its reliability. There is no guarantee that a reliable system is valid, but assuredly an unreliable system must be invalid. Studies of the reliability of psychiatric diagnosis provide information on the upper limits of its validity. This paper discusses some of the difficulties in appraising diagnostic reliability, offers a re-analysis of available data from the literature, and suggests a possible course of action to improve psychiatric diagnosis…
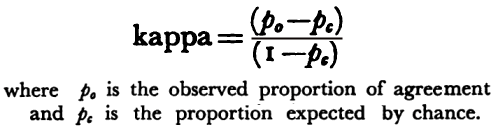
There are no diagnostic categories for which reliability is uniformly high. Reliability appears to be only satisfactory for three categories: mental deficiency, organic brain syndrome [but not its subtypes], and alcoholism. The level of reliability is no better than fair for psychosis and schizophrenia and is poor for the remaining categories.
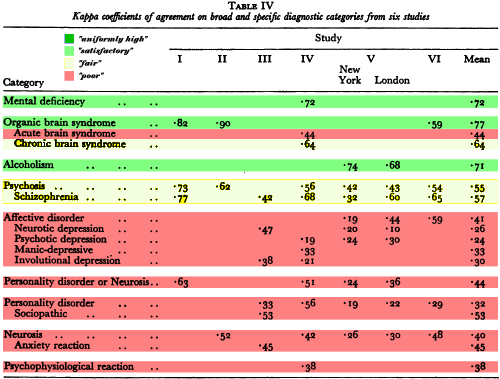
The reliability of psychiatric diagnosis as it has been practised since at least the late 1950’s is not good. It is likely that the reasons for diagnostic unreliability are the same now as when Beck et al studied them. They found that a significant amount of the variability among diagnosticians was due to differences in how they elicited and evaluated the necessary information, and that an even larger amount was due to inherent weakness and ambiguities in the nomenclature. Since that time there have been two major innovations which may provide solutions to these problems.Several investigators have developed structured interview schedules which an interviewer uses in his examination of the patient. These techniques provide for a standardized sequence of topics, and ensure that variability among clinicians in how they conduct their interviews and in what topics they cover is kept to a minimum. For rating the pathology observed, these schedules contain precoded items which explicitly define the behaviours to be rated rather than relying on technical terms which have different meanings to different clinicians.
With respect to improving the nomenclature, the St.Louis group (Feighner et al) has offered a system limited to 16 diagnoses for which they believe strong validity evidence exists, and for which specified requirements are provided. Whereas in the standard system the clinician determines to which of the various diagnostic stereotypes his patient is closest, in the St. Louis system the clinician determines whether his patient satisfies explicit criteria. For example, for a diagnosis of the depressive form of primary affective disorder the three requirements are dysphoric mood, a psychiatric illness lasting at least one month with no other pre-existing psychiatric condition,and at least five of the following eight symptoms: poor appetite or weight loss; sleep difficulty; loss of energy; agitation or retardation; loss of interest in usual activities or decrease in sexual drive; feelings of self-reproach or guilt; complaints of or actually diminished ability to think or concentrate; and thoughts of death or suicide.
A consequence of the St. Louis approach is the necessity for an ‘undiagnosed psychiatric disorder’ category for those patients who do not meet any of the criteria for the specified diagnoses. In actual use, this category is applied to 20-30 per cent of newly-admitted in-patients. These two approaches, structuring the interview and specifying all diagnostic criteria, are being merged in a series of collaborative studies on the psychobiology of the depressive disorders sponsored by the N.I.M.H. Clinical Research Branch. We are confident that this merging will result not only in improved reliability but in improved validity which is, after all our ultimate goal.
In Baseball, the uniforms change, the stadiums grow, the ticket and hot dog prices escalate with the players’ salaries, and the records very slowly fall. But the box scores stay the same and the distance from home to first base never changes. When you have a losing season, you don’t argue with the Stats, you get a new Manager, add a relief pitcher, but you sure don’t fight with the way the game is played.
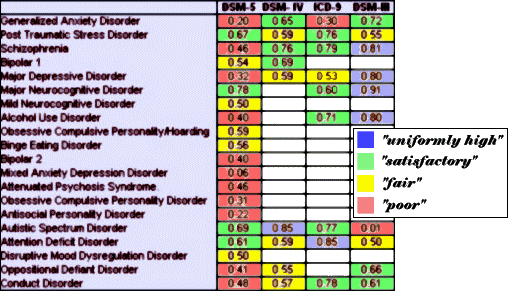
There is also some shifting of the goalposts happening this week at the APA meeting in Philadelphia. The DSM-5 leaders have announced a new ordinal scale of Kappa values that “spins†their field trial results for maximum public relations effect. As you said in your final Table in self evident, lousy Kappas are now being deemed ‘acceptable’ and poor Kappas are being called ‘realistic.’
It’s a bit like Humpty Dumpty: ‘When I use a Kappa,’ Humpty Dumpty said, in rather a scornful tone, ‘it means just what I choose it to mean — neither more nor less.’ ‘The question is,’ said Alice, ‘whether you can make Kappas mean so many different things.’
You know in psychometric assessment, kappa’s below 0.80 are unacceptable.
I didn’t know the actual cut-off, but I knew it was much higher than these people were talking about. I wish the psychometrist Gurus would weigh in here. I think it would help with some much needed reality testing…
OK psychometric testing is a high standard. But the state of the art as to reliability (rater agreement ) is offered as:
Interpreting the Magnitude of Kappa
Landis and Koch (45) have proposed the following as standards for strength of agreement for the kappa coefficient: ≤0=poor, .01–.20=slight, .21–.40=fair, .41–.60=moderate, .61–.80=substantial, and .81–1=almost perfect. Similar formulations exist,(46–48) but with slightly different descriptors. The choice of such benchmarks, however, is inevitably arbitrary,(29,49) and the effects of prevalence and bias on kappa must be considered when judging its magnitude.
Even by this standard, the DSM-5 reliability studies are woeful in terms of results. Or maybe not: If we accept the reliability of psychiatric diagnosis as FAIR being our standard, then the DSM-5 did its job!!!!
Londoners were better than New Yorkers at recognizing schizophrenia? !!
Interesting. All the big money-makers, pharma-wise, have crappy kappas in DSM-5.
Overreaching come to roost?
News on the DSM5 from NYT
Psychiatry Manual Drafters Back Down on Diagnoses
http://www.nytimes.com/2012/05/09/health/dsm-panel-backs-down-on-diagnoses.html?_r=2&smid=tw-nytimes&seid=auto