When first we practise to deceive!
Sir Walter Scott
In the last post, I was talking about the need for the raw data from clinical trials to be posted after discovering that the STUDY 329 was finally available. The format is tough, an image based pdf file. The only way to get the numbers out where they can be analyzed that I know is to copy them one by one into a spreadsheet or database program. Thus, the absence of posts here while I took a day+ to do that [only for the Paxil group so far]. This is a plot of the raw data for the HAM-D [primary outcome measure]. I expect I’ll do the Placebo and Imipramine groups sooner or later, but this is enough to take a stab at a point [and give my bifocals a rest]:
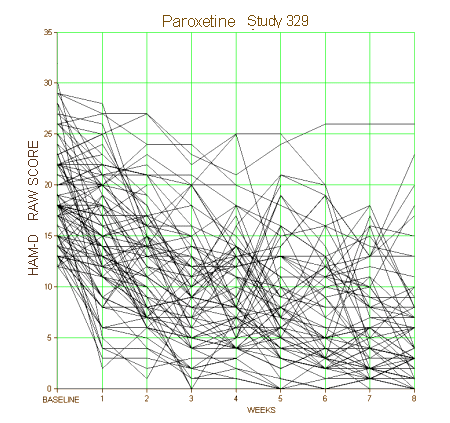
Each of those lines represents one of 91 depressed teenagers on Paxil – some dropouts, some failures, some successes. Obviously, it’s meaningless without the placebo group to compare it to, but just looking at the raw results, the variability is striking. And each nodal point on the graph is the sum of the responses to seventeen questions. There’s an ocean of variables in that graph.
There are a number of mathematical maneuvers we can make with these garbled lines once we see them. We can express them as change from the baseline or % change from the baseline like Keller et al did. We can reduce the whole thing down to a bland arithmetic mean,
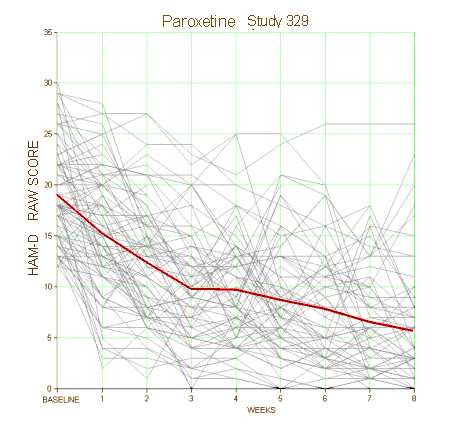
[red line = arithmetic mean]
or the least squares mean. We can quantify the variability as a standard deviation, or a standard error of the mean. We can define ‘cut-offs’ like,
![]()
We can do the same things with the Placebo response, and then do all manner of statistical tests to compare Paxil to Placebo.
All of these mathematical gyrations are operations specifically designed to reduce confusion and put the spaghetti of raw data into a format that allows comparisons that ultimately address the efficacy of Paxil in teens. But these same machinations that are supposed to bring clarity to the question can [and have been] used to pervert and hide those very meanings, to disembody and depersonalize these teenagers, and to be used in the service of something other than figuring out if Paxil helped them – to hide rather than explicate the meaning. We know that’s what happened with Study 329. That tangle up there was turned into something using the tools of legitimate science, but that something was not the truth.
So the reason I spent more time than I wanted to transcribing the raw data into something that could be analyzed and displayed [and will likely waste a few more days doing the same thing with more of the data] is that I want to make the loud case that if this information had been available eleven years ago, all of this wouldn’t have happened. GSK, Sally Laden, and the guest authors couldn’t have published a study that said, "Paroxetine is generally well tolerated and effective for major depression in adolescents." The only reason they could say that is because this raw data wasn’t available to the curious or the critics. The authors could twist it and turn it into something it wasn’t, because it couldn’t be checked.
You Sir, are a genius. Be great to see the outcome of your findings. I’ve managed to obtain the polled analysis Glaxo use to concur [on the patient information leaflets] that withdrawal isn’t really an issue. I asked Glaxo for these pooled studies, they refused. Being in NZ, however, one can get the info elsewhere. You have my new email address, right?
Fantastic work Doc.
These researchers stop at nothing to help pharma expand marketshare.
It’s shameful.
Duane
The handling is Study 329 is worthy of study and raises questions about child psychiatry that need to be examined. However, I think you are making a mistake in using the term “guest authors.” If you examine carefully the documents available at the UCSF archive you will see that this is Dr. Neal Ryan’s study from start to finish. If you examine Dr. Ryan’s career I believe you will also find that he is a true believer and that the voice you hear echoing through the years, over a decade now since the paper was published, is not Laden’s, certainly not McCafferty’s (who raises concerns that are overruled by Ryan and Keller), not even GSK’s, but Ryan’s. Those documents indicate that Keller (together with Ryan) originally pitched 329 to GSK, were the primary investigators (along then with GSK’s McCafferty) on the study, Ryan was aware for years how suicidal ideation and actions were being coded, it was the researchers who chose to code those events as unrelated to medication and never delineated why, it’s almost certainly the main authors who wrote the response to reviewers questions regarding the paper’s discussion of these events (saying essentially that it would not have been “responsible” to draw conclusions from those numbers, and it was Ryan who wrote the draft of the response to Jureidini’s letter to JAACAP (even maintaining it’s tone over the objection of McCafferty). Study 329 and the subsequent paper reflect Ryan’s, and likely AACAP’s views, and GSK marketing gave it a megaphone. I think you would be better served looking at this through the same lens you used to examine the origin of the DSM III. Scientists are skilled at obtaining funding and slanjng information to fit a story. By using the term “guest authors” you may risk seeing the dog as the tail. Please please keep covering this story, but please keep more in mind the active role that Ryan and AACAP play in it. And that some of them, particularly Ryan, appear driven by a genuine belief that they are helping children. And, that if you examine things closely I think you’ll see that Ryan was influenced more by his beliefs than by GSK’s money. In that sense he is right (about himself at least) in saying the emperor has no clothes. This is something that understandably lawsuit against HSk had little interest in examining. However, as you examined with the DSM III, those beliefs can have great impact. Ryan may have heavily slanted the presentation of Study 329 in what he believed was the need for children to receive adequate treatment through their pediatricians. I’m convinced that Ryan truly viewed Study 329 as indicating that Paxil was effective and safe in a pediatric population (particularly after reading his response letter(s) to AACAP). I remain unconvinced that the study should be retracted. However, I believe it is a valid question to ask if there is an issue with him having looked at Study 329 and drawn that conclusion. And that, despite the concerns raised by the reviewers at JAMA and JAACAP, other researchers on the study (both academic and within GSK’s research division), and other colleagues shortly after publication, that Ryan and AACAP had left that message squarely in place about Paxil over many years (my impression is that even doctors who use SSRIs in kids don’t tend now to use Paxil). Even as GSK’s marketing division used that message to widely promote Paxil’s use among pediatricians. To my mind, that emperor has clothes.
For example see:
http://dida.library.ucsf.edu/pdf/tuu38h10
http://www.healthyskepticism.org/files/docs/gsk/paroxetine/study329/20001004LadentoKeller.pdf
Sorry for the typos in the earlier message.
Just a tip: If you pull a pdf or image file into Google Docs (now Google Drive), docs.google.com/ , you can translate it into text or other editable format — use File>Download As.
Google has graciously built an optical character recognition (OCR) function into Docs. http://support.google.com/docs/bin/answer.py?hl=en&answer=176692
I cannot tell you how much I appreciate this website, its author and its commenters. I have my own “fight back” going and you help me so much!!