There is good news and bad news about enrolling patients in clincal trials. First, the good news – 89 percent of all trials meet their enrollment goals. Now, the bad news – 48 percent of the trial sites miss enrollment targets and study timelines often slip, causing extensions that are nearly double the original duration in order to meet enrollment levels for all therapeutic areas. This sobering finding was contained in the latest report from the Tufts Center for the Study of Drug Development, which examined patient recruitment and retention practices in clinical trials. The report suggests that drugmakers and contract research organizations may have difficulty because they rely on traditional approaches. The analysis was based on more than 150 clinical studies involving nearly 16,000 sites in different countries.
Here are some other key findings: 89 percent of all trials meet enrollment goals, but this also means that 11 percent of sites in a given trial typically fail to enroll a single patient. In other words, one out of 10 sites end up without any patients. Meanwhile, 37 percent fail to enroll enough patients, 39 percent meet their enrollment targets and 13 percent exceed their targets. And for a given Phase II or Phase III trial, one of every eight sites exceeds enrollment targets. The highest site activation rates are in Western Europe, which has a 93 percent rate. A close second is Eastern Europe with 92 percent, followed by the Asia/Pacific region with a 91 percent rate. The lowest rates are in North America, with 87 percent, and Latin America, with 80 percent. “Enrollment achievement rates vary by region, ranging from 75 percent to 98 percent of targeted levels, with Asia/Pacific and Latin America achieving the highest rates,” Tufts writes.
What else? Well, half of all patients screened complete clinical trials overall, though there is wide variation by therapeutic area, according to Tufts. For instance, endocrine studies have the lowest trial completion rates with just 42 percent of all patients screened. And oncology studies tend to have shorter timeline extensions to reach enrollment levels, compared to endocrine and CNS studies, which have the longest average extensions. And this is interesting: the vast majority of drugmakers and CROs – roughly 90 percent – use traditional recruitment tactics, including physician referrals and mass media, such as newspapers, flyers, radio, and television. Only 14 percent use what are considered non-traditional approaches, such as Facebook banner ads, Twitter, YouTube, electronic medical record reviews, social networking, and online data mining. And this is almost done exclusively in North America, Tufts writes.
Why? The “highly limited use of non-traditional recruitment tactics is a function of real and perceived restrictions by global region, aversion to high-risk approaches, and limited recruitment budgets,” Tufts writes. On a related note, centralized recruitment and retention programs use traditional tactics and tend to avoid nontraditional approaches. And 32 percent of studies do not even receive centralized recruitment support [here is the Tufts statement].
UPDATE: We are reminded that Pfizer recently undertook an example of ‘non-traditional’ recruitment tactics. Last June, the drugmaker discontinued enrollment in a study that used social media almost exclusively to recruit patients who would participate from home by using computers and smartphones instead of going to a clinic or doctor’s office for medicine and check-ups. Pfizer hoped to create a model for saving money that would rely on personal technology to more easily recruit patients and monitor their progress, but was unable to generate a sufficient number of participants. An updated pilot, though, has been planned [read more here].
When I used to read an article in a medical journal with its formalized statements of the objectives, methods, results, and conclusions, in my mind I saw the patients from my life as a doctor. I didn’t see recruits. I don’t imply here that there’s something wrong with being a recruit, but it seems like that might be a different lot from what are called help-seeking or self-referred patients. I know I didn’t visualize this: "traditional recruitment tactics, including physician referrals and mass media, such as newspapers, flyers, radio, and television" or "non-traditional approaches, such as Facebook banner ads, Twitter, YouTube, electronic medical record reviews, social networking, and online data mining" [well, maybe " physician referrals"]. And I didn’t envision patients like the ones on the left below [even if they were on the graph in front of me]. I guess I looked at the difference – like on the right:
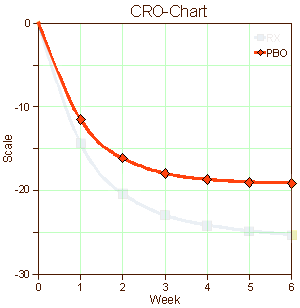
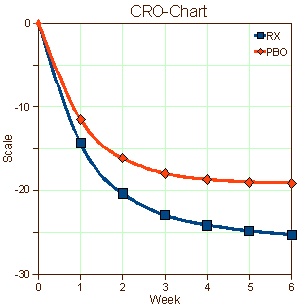
… I’m used to a lot of people feeling better when they talk about things to somebody that knows how listen. It’s a human thing. Sometimes that’s all that’s needed, and sometimes there’s more…
I suppose that if I were a legitimate, dedicated clinical trials person, I’d rack my brain about how to recruit depressed patients for my studies or about how to retain them for the duration of the trial. Both things are genuine problems. And when the data came in, I’d look at those placebo responses as another real problem and try to figure out what to do about that in my next trial or ways to understand it. And if I were a drug company executive who had $pent a lot of money developing a drug hoping to $ee a blockbu$ter in my future, I might beam when I $aw that graph on the right. But I’m not any of those things. I’m an old doctor who has seen a jillion patients over the years. And what I’m thinking right now is that the significant thing about those graphs of antidepressant trials is that recruits and the patients are different populations of people. They may overlap, but they just aren’t equivalent.
I haven’t got any idea about what to do about any of this. I suppose I could be pristine and make some eloquent appeal about using only help-seeking [altruistic] patients at a single site – all of the things in the middle column in that table from the previous post. But that’s naive, because if I put myself in the place of a real clinical trials person, that’s just downright impractical. One thing I do think is that I’m more sympathetic to the mandates of the FDA. They’re charged to certify safety and efficacy [lite], not to tell us if the drugs are good or not. With this kind of information, they couldn’t do that. That graph on the right says, "this drug has statistically significant antidepressant properties." And that’s true. But I’m not even sure we could compare effect size across studies, because that might be a function of recruitment methods [we can compare active comparators]. But that’s hardly the end of the story. The testing with real patients rather than recruits comes after that.
We all know that data transparency is a good idea [at least those of us unconnected with the profitability of drugs]. We need to keep people from playing with the clinical trial results. That much is certain. But what about the recruits versus the patients issues? Once a drug is approved and released into the patient world, we sort of drop the ball. The FDA has the power to require phase 4 studies, and adverse reactions can be reported to them. Dr. David Healy is trying to beef that up with his RxISK site, focused primarily on safety. But what about our stopping pretending that FDA Approval is the end of something and considering seeing it as the beginning of a patients’ clinical trial – being systematic about keeping up with what happens in the real world and making the results available to doctors and patients alike. Maybe declare a moratorium on advertising on t.v. and elsewhere for the first year after FDA approval. We could stick the time needed to test patients on the end of patent exclusivity. I don’t know how one might do such a thing [maybe fill out a simple form when you pick up a new prescription – or don’t], but it would sure cut a lot of losses from the patient’s point of view.
Two things:
1. I think that it is possible that even people who are big D depressed will feel some relief at speaking to someone.
2. A major problem may be the culture of medicine — many doctors do not believe their patients when they complain. I speculate that this comes from their education, where they are told to be quiet and listen to the authority, and then that they are the authority in their turn. Some patients benefit from, or at least enjoy, this authority. But it can make it very easy to turn a blind eye to patient reports, especially if you don’t like the patient in question.
an industry problem across illness sectors
http://www.sciencedaily.com/releases/2012/05/120503142540.htm
Biased Evidence? Researchers Challenge Post-Marketing Drug Trial Practices
“Rigorously designed and executed research has a critical role in improving patient care and restraining ballooning health care costs,” said Kimmelman, associate professor of biomedical ethics at McGill. “There is currently a push to streamline the ethical review of research. In this process, oversight systems should be empowered to separate scientific wheat from marketing chaff.”
It wouldn’t be too hard to establish a central database. Give patients a number, report all the drugs prescribed, their strength and schedule, report effects. This would require full disclosure so that patients understand that the drugs may have undesired effects. (It might help to stop using the term “side-effects”.) And it would require doctors to explain that stopping the medication might cause adverse effects that can be conflated with a return to “depression,” so that if the patient wants to discontinue, it would be best to do so on a schedule to reduce “withdrawal” like effects. The effects of discontinuation should also be reported.
It would take about three minutes.
If the website were open source, I’ve no doubt that it would be well mined by people such as yourself (Micky), who like numbers.
I find it interesting that while one meta-analysis finds that placebo response has increased steadily over a 20-yr period, so too has drug response (in antidpressant trials). The graph is shown here: http://asserttrue.blogspot.com/2013/03/placebos-are-becoming-more-effective.html The drug response has crept up at the same rate as placebo response, which tells me one is the same as the other (one is an “enhanced placebo response” and one is placebo response). Possibly. In any case, when you enroll people who are desperate for free medical care into a trial and pay them money to stay in it, it seems such people are only too glad to tell researchers whatever they want to hear, basically; so it’s no wonder placebo response has crept upward and upward.