I know I sometimes get kind of hung up on numbers, and it just happened. I was looking at Wagner et al in the last post because it was ghost-written, but I did read the abstract and something stuck with me. It’s highlighted in red below, "[effect size=2.9]". The effect size is a measure of the strength of an effect and is the simplest of calculations: it’s the difference in the means of the two groups divided by the standard deviation.  Besides being an index of the strength of an effect, it also normalizes things so different studies can be compared. The usual range is 0.25 = weak, 0.50 = moderate, and 0.75 = strong. So what’s with effect size=2.9? It doesn’t make any sense. So I went back and pulled the whole paper to calculate it myself. Curious George, I guess…
Besides being an index of the strength of an effect, it also normalizes things so different studies can be compared. The usual range is 0.25 = weak, 0.50 = moderate, and 0.75 = strong. So what’s with effect size=2.9? It doesn’t make any sense. So I went back and pulled the whole paper to calculate it myself. Curious George, I guess…
Besides being an index of the strength of an effect, it also normalizes things so different studies can be compared. The usual range is 0.25 = weak, 0.50 = moderate, and 0.75 = strong. So what’s with effect size=2.9? It doesn’t make any sense. So I went back and pulled the whole paper to calculate it myself. Curious George, I guess…by Wagner KD, Robb AS, Findling RL, Jin J, Gutierrez MM, Heydorn WE.American Journal of Psychiatry. 2004 161[6]:1079-1083.
OBJECTIVE: Open-label trials with the selective serotonin reuptake inhibitor citalopram suggest that this agent is effective and safe for the treatment of depressive symptoms in children and adolescents. The current study investigated the efficacy and safety of citalopram compared with placebo in the treatment of pediatric patients with major depression.METHOD: An 8-week, randomized, double-blind, placebo-controlled study compared the safety and efficacy of citalopram with placebo in the treatment of children [ages 7-11] and adolescents [ages 12-17] with major depressive disorder. Diagnosis was established with the Schedule for Affective Disorders and Schizophrenia for School-Age Children-Present and Lifetime Version. Patients [N=174] were treated initially with placebo or 20 mg/day of citalopram, with an option to increase the dose to 40 mg/day at week 4 if clinically indicated. The primary outcome measure was score on the Children’s Depression Rating Scale-Revised; the response criterion was defined as a score of < 28.RESULTS: The overall mean citalopram dose was approximately 24 mg/day. Mean Children’s Depression Rating Scale-Revised scores decreased significantly more from baseline in the citalopram treatment group than in the placebo treatment group, beginning at week 1 and continuing at every observation point to the end of the study [effect size=2.9]. The difference in response rate at week 8 between placebo [24%] and citalopram [36%] also was statistically significant. Citalopram treatment was well tolerated. Rates of discontinuation due to adverse events were comparable in the placebo and citalopram groups [5.9% versus 5.6%, respectively]. Rhinitis, nausea, and abdominal pain were the only adverse events to occur with a frequency exceeding 10% in either treatment group.CONCLUSIONS: In this population of children and adolescents, treatment with citalopram reduced depressive symptoms to a significantly greater extent than placebo treatment and was well tolerated.
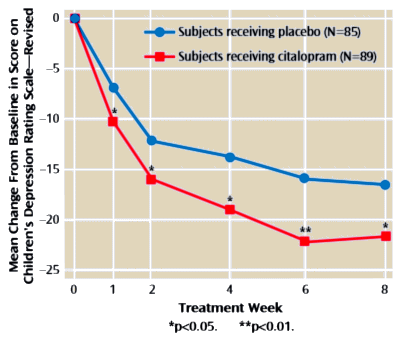
Well, they give us the mean CDRS-R scores at the baseline and the standard deviations…
… Mean Children’s Depression Rating Scale Revised scores at baseline were 58.8 [SD=10.9] and 57.8 [SD=11.1] in the citalopram and placebo groups, respectively, indicative of moderately severe illness.
And they show us that there’s about a 5 point difference at week 8 on the graph, but they didn’t give us either the Means or the Standard Deviations at week 8 anywhere that I could find. Since the Formula is Effect Size = [Difference in the Means] ÷ [Standard Deviation], we could work backwards as in 2.9 = 5 ÷ [Standard Deviation] which comes out with a Standard Deviation = 1.72. Given they started with a Standard Deviation = ~11, 1.72 has to be wrong. As I scratched my head in confusion and pondered, I noticed these references below the abstract on PubMed:
- Child psychopharmacology, effect sizes, and the big bang. [Am J Psychiatry. 2005]
- Child psychopharmacology, effect sizes, and the big bang. [Am J Psychiatry. 2005]
- Child psychopharmacology, effect sizes, and the big bang. [Am J Psychiatry. 2005]
These were comments on the article in the AJP. I wasn’t the first to wonder about that effect size. Commenter Andres Martin had named it the big bang [a bit of AJP humor]. In their response to comments, Wagner et al said:
Dr. Martin and colleagues inquire about the value of 2.9, which was calculated as the quotient of the least square mean, divided by the common standard error of the mean for each treatment group. With Cohen’s method, the effect size was 0.32.
I have no clue where that first part came from, but the effect size=0.32 is more like it – in the weak-to-moderate range. But then there were those other numbers:
… Citalopram treatment showed statistically significant improvement compared with placebo on the Children’s Depression Rating Scale — Revised as early as week 1 [F=6.58, df=l,150, p<0.05], which persisted throughout the study. At week 8, the effect size on the primary outcome measure, Children’s Depression Rating Scale-Revised [last observation carried forward], was 2.9. Additionally, at endpoint more citalopram-treated patients [36%] met the prospectively defined criterion for response than did placebo-treated patients [24%], a difference that was statistically significant [x²=4.178, df=l, p<0.05]. The proportion of patients with a CGI improvement rating <2 at week 8 was 47% for the citalopram group and 45% for the placebo group [last observation carried forward values]. For the CGI severity rating, baseline values were 4.4 for the citalopram group and 4.3 for the placebo group, and endpoint values [last observation carried forward] were 3.1 for the citalopram group and 3.3 for the placebo group.
They report 36% responders to Citalopram as opposed to 24% to Placebo. The NNT [Number needed to Treat] would be 1 ÷ [0.36 – 0.24] or NNT = 8.3. In prose, that translates to, "You have to treat 8 people with Citalopram before you get one that does better than they would’ve done on a Placebo" – which is lousy. And for the chi square, I got [x²=2.852, df=l, p=0.0912] with the Yates correction and [x²=3.439, df=l, p<0.0637] uncorrected. But there was also the CGI [Clinical Global Impressions] result which is the observation of improvement: Placebo 45%, Citalopram 47%. And the severity: Placebo 4.3, Citalopram 4.4 before, and Placebo 3.3, Citalopram 3.1 at 8 weeks. That’s no difference at all. So the subjects showed no overall observed improvement with Citalopram. My Conclusion: A weak at best and clinically insignificant signal. In their response to criticisms, Wagner et al said:
We believe that the results of our study, which demonstrated a significant difference between citalopram and placebo beginning at week 1, is clinically meaningful, particularly at a time when there have been so few antidepressants shown to have superiority to placebo for depressed children.
That final comment is pretty bizarre, given that by the time it was written, Dr. Wagner herself had authored three previous articles claiming the effectiveness of SSRIs in youth [collusion with fiction…].
| I finally located this study [CIT-MD-18] under Lexapro in Drugs@FDA. The answer to Psycritic’s original point is pretty complicated. They allowed this study [Wagner et al] to count in the Lexapro application for the pediatric MDD Approval because it is a racemic mixture. Wagner et al and one Lexapro trial were used for approval in adolescents, but it was only Lexapro that was approved. The NDA found the CDRS-R difference significant [p=0.038] but not the CGI [no mention of ‘responders’]. The bottom line is that this [shaky] clinical trial was essential to the pediatric approval. |
How was that for a wild goose chase? Actually, I kind of enjoyed it. I had originally just looked at the graph in Wagner et all and assumed it was a positive study. Coming back to it after seeing that [effect size=2.9] value and realizing how shaky it really was was a good reminder that with these clinical trials, "all that glitters is not gold." It was only a positive study by the letter of the law, not by direct observation [CGI].
This actually mirrors my own experience. When I first started volunteering after retirement, I worked in a Child and Adolescent clinic for a while. I tried SSRIs in a few depressed adolescents [actually Celexa®] without any luck. Then I had a case of Akathisia [unknown to me at the time], and that was the end of that little experiment. Actually, it was that case that got me looking at the psychopharmacology literature and ultimately lead to this blog. I looked at it initially to "catch up," but ended up "catching on." I did use SSRIs in a few adolescents with OCD-like symptoms [compulsive "cutting"] with notable success – though after the Akathisia case, I saw them frequently [and worried]. I actually stopped working in that clinic because I was being pressured to prescribe more. In those several years, I never saw a depressed adolescent who was just "depressed." They were all cases with complex family and interpersonal issues – way more psycho·social than bio·…
Not the math major thanks for showing your work, it all made sense seeing the problem worked out on paper.
Troubling is the material I have seen shows antidepressants effectiveness falling off at week 12 with very little effectiveness at week 16. The use of an eight week test period, I am sure is a marketing idea, is a way to show effectiveness. How do we move forward knowing the study was rigged from the start and with such glaring math issues as to be discredited?
My only conclusion is that pharma feels that with a big name author and enough push by the reps they can manufacture another blockbuster.
Steve Lucas
We believe…?
The thinking is this: Side effects are almost non-existent, so why not throw this stuff at children too?
Except the evaluation of side effects was also dishonest….
There really should be advocates for the children who question the parents and look for reasons why the children/teens might be suffering. I see psychiatry ganging up on children with parents and ignoring the children’s needs. I’m not advocating a mother-blaming Freudian perspective, but the fact that many children suffer problems due to pathology in their families, or are the victims of bullies outside of their families.
I simply do not see what would stop a psychiatrist from labeling and drugging a child who is a victim of abuses. It’s morally bankrupt for doctors to take a parent’s word for that there must be something wrong with the children.
Thank you for these last two posts. Your thoroughness and diligence amaze me and make me envious. I am a child psychiatrist working in an adolescent inpatient unit. Though I share your impression that depression reactive to psychosocial factors is the more common variant in adolescents, in an inpatient unit I do see many patients with more “biological” types of depression, such as psychotic, catatonic and melancholic depressions, many times in the context of a bipolar course. These patients sometimes improve dramatically with biological treatments such as medications and ECT. Another small note: CGI is not a subjective evaluation by the patient, but by the clinician.