This is just some fluff. After all this time looking at the industry-funded clinical trials [RCTs], I’ve learned a few tricks for spotting the mechanics of deceit being used, but I realize that I need to say a bit about the basic science of RCTs before attempting to catalog things to look for. Data Transparency is likely coming, but very slowly. And even with the data, it takes a while to reanalyze suspicious studies – so to these more indirect methods. I expect there will be a few more of these posts along the way – coming mostly on cold rainy week-end days like today when there’s not much else going on. If you’re not a numbers type, just skip this post. But if you’re someone who wants to contribute to the methodology of vetting these RCTs, email me at 1boringoldman@gmail.com. Examples appreciated. It’s something any critical reader needs to know how to do these days…
The word sta·tis·tics is derived from the word state, originally referring to the affairs of state. With usage, it has come to mean general facts about a group or collection and the techniques used to compare groups. In statistical testing, we assume groups are not different [the null hypothesis], then calculate the probability of that assumption. If it’s less than some value called alpha [0.05], we reject the null hypothesis and assume the groups are significantly different.
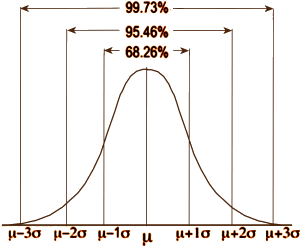 In statistical testing, assumptions abound. For continuous variables, we assume that the data follow a normal distribution, so we can simplify the dataset into just three numbers: the mean [μ], the standard deviation [σ], and the number of subjects [n]. In an RCT, with just those numbers for the placebo group and the drug group, we can calculate the needed probability. In the normal distribution, all the items between two standard deviations on either side of the mean make up 95% of the sample. Values outside those limits make up only 5% of the sample. In doing statistical testing for the difference between two groups [assuming for the moment an equal σ and n], when the probability of the null hypothesis is 0.05 or less [p < 0.05], we feel confident that the groups are significantly different. But that only tells us that the groups are different – not how different.
In statistical testing, assumptions abound. For continuous variables, we assume that the data follow a normal distribution, so we can simplify the dataset into just three numbers: the mean [μ], the standard deviation [σ], and the number of subjects [n]. In an RCT, with just those numbers for the placebo group and the drug group, we can calculate the needed probability. In the normal distribution, all the items between two standard deviations on either side of the mean make up 95% of the sample. Values outside those limits make up only 5% of the sample. In doing statistical testing for the difference between two groups [assuming for the moment an equal σ and n], when the probability of the null hypothesis is 0.05 or less [p < 0.05], we feel confident that the groups are significantly different. But that only tells us that the groups are different – not how different.
 In this simple two group example, calculating the p value depends on having the means [μ1 and μ2], the standard deviations [σ1 and σ2], and the two sample sizes [n1 and n2]. And this is about as far as they got in my medical school version of a statistics course in the dark ages called the 60s
In this simple two group example, calculating the p value depends on having the means [μ1 and μ2], the standard deviations [σ1 and σ2], and the two sample sizes [n1 and n2]. And this is about as far as they got in my medical school version of a statistics course in the dark ages called the 60s  [only scratching the surface of the field]. So those of us doing research had to add some other degrees. They do a better teaching job in these modern times [with computers to do the heavy number crunching instead of the calculators that shook the table and sounded like Gatling guns]. And with the increased computer power came much more sophisticated statistical testing allowing the evaluation of many more factors in the models.
[only scratching the surface of the field]. So those of us doing research had to add some other degrees. They do a better teaching job in these modern times [with computers to do the heavy number crunching instead of the calculators that shook the table and sounded like Gatling guns]. And with the increased computer power came much more sophisticated statistical testing allowing the evaluation of many more factors in the models.
This is a case where one wonders if the technological advances have been all that helpful. In the past, medications were evaluated on clinical grounds. The efficacy scale was simple. It had it doesn’t work, it sometimes works, and it works – a scale suited to an effective medications. With the modern clinical trials, much smaller differences are the rule – sometimes in the range of absurdity. So, as most people know in the abstract, a p < 0.05 doesn’t necessarily denote clinical significance. It may mean absolutely nothing or conversely something of real value. But in spite of that knowledge, our eyes are invariably drawn to the ubiquitous p value like a magnet.
One attempt to get at a more relevant index of efficacy is to standardize the magnitude of the difference between the means of the two samples in some way – for example Cohen’s d [a way to compute the strength of the effect]. It’s the difference in the means expressed as a percent of the pooled standard deviation. Back to assuming an equal σ and n in the two groups, it would be:
d = (μ1 – μ2) ÷ σ
While there’s no strong standard for d like there is for p, the general gist of things is that: d = 0.250 [25%] is weak, d = 0.50 [50%] is moderate, and d = 0.75 [75%] is strong. Note: for groups of unequal size or distribution, the pooled σ is:
![]()
This graphic makes this point better, and gets around to why I’m writing this:
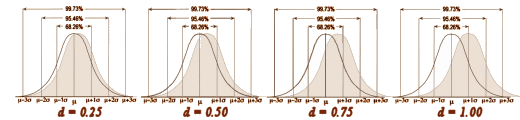
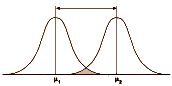 Even a strong Cohen’s d isn’t a huge separation – plenty of overlap still in the picture. So when you’re looking at Effect Sizes, don’t think it looks like the figure on the left [d = 4]. You’re usually still back in the land of sometimes when you’re looking at these Effect Sizes in a Clinical Trial report in a journal article.
Even a strong Cohen’s d isn’t a huge separation – plenty of overlap still in the picture. So when you’re looking at Effect Sizes, don’t think it looks like the figure on the left [d = 4]. You’re usually still back in the land of sometimes when you’re looking at these Effect Sizes in a Clinical Trial report in a journal article.
Another point. You may have noticed that you need μ, σ, and n to calculate statistical significance, but only μ and σ to calculate Cohen’s d. The strength of effect is independent of the sample size. You can figure out how these thing relate to each other. With a drug that has a moderate effect [eg d = 0.50] you need only a small sample size to achieve statistical significance [even less if it’s strong]. But with a weak effect [d = 0.250], you need to have a whole lot more subjects in your study. Again, assuming two groups with equal size and distribution, the relationship looks like this:
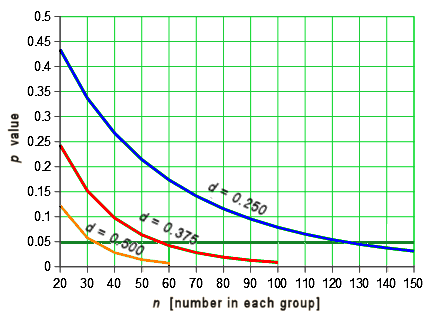
While these are the nuts and bolts of how one does Power Analysis when planning a clinical trial to figure out the needed sample size, that’s not why this graph is here. Most RCTs have p values listed, but many don’t have any version of the Effect Size [Cohen’s d, Odds Ratio, NNT, etc], probably because they’re weak sisters. So one thing to look for is that they have very large sample sizes. It’s in order to get that magic p < 0.05 they’re looking for to legitimize a weak effect. When the Effect Size is missing, you often have enough information to calculate it using the formulas above. Note: It’s common to have the Standard Error [se or sem] rather than the Standard Deviation [sd or σ]. But it’s easily converted using the formula:
se = σ ÷ √n or σ = se × √n
Here is a sample of an effect size that didn’t add up to a hill of beans but that was presented as having clinical significance – in American Journal of Psychiatry, no less.
How did they end up originally printing it with errors that were not attributed to you?
James, if you go to the earlier version you will be able to compare the two texts. Basically, the subeditor decided to add his or her personal touch to my text, and in the process mangled several passages. Nancy Andreasen was quite understanding about righting the record. I had an even worse experience with a full paper in JAMA a few years ago. The subeditor completely rearranged the body of the paper, altering the flow of our material and losing the impact in the process. We objected, and the subeditor was removed from that task.
Thanks for such a clear concise explanation. I appreciate all the work you put into your posts.
I foolishly had this quaint idea that editor-writer was a back and forth collaboration. Seems the rush to publish without double checking is a real problem.
And today there’s really no excuse with Internet programs that make edit and reedit so easy.
The wild card is the human factor, James. The subeditor at AJP thought s/he was God’s gift to mere scientists, and s/he didn’t show me the changes before publication of my letter to editor. At least in the case of JAMA we caught the issue (same diagnosis at work) in the galley stage.
I actually find it disturbing that they would change your document and publish it without a final draft approval.
I wrote a lot of forensic reports and I hire a full-time editor as I believe you cannot edit your own work. We may be sending back and forth six or seven times until I am satisfied. This is for a work product of 30 or so pages that three or four people will probably read, or more likely, skim.
The idea that something can be published in a major journal in such a slipshod manner is bothersome. It is even more troubling that editors seem to be ok with the lack of attention to detail, so I wonder about all their own research. But then again, looking at the profit margins of academic publishing groups, and the quality of the published material, it is not surprising.
This post is exceptional, thanks for all your hard work. The graphs showing the overlap in effect sizes (or lack thereof) are amazingly helpful, as is the “power” graph. I’ve known these concepts in statistical terms but having an image to attach is so much more meaningful.