In spite of an undergraduate mathematics degree and statistical training in a subsequent academic fellowship, I think I had retained a relatively naive yes/no way of thinking rather than seeing various shades of maybe. My brother-in-law is a social psychologist who taught statistics and for a time studied the factors involved in voting patterns. It all seemed way too soft for the likes of me to follow. Like many physicians, I’m afraid I just listened for the almighty yes/no p-value at the end. So when I became interested in the clinical drug trials that pepper the psychiatric literature, I was unprepared for the many ways the analyses can be manipulated and distorted. I was unfamiliar with things like power calculations and effect sizes. So as I said recently, I had previously read that little thing at the top… [the abstract] without critically going over the body of the paper, making the assumption that the editor and peer reviewers had already done the work of vetting the article for me.
PLOS Medicineby John P. A. IoannidisAugust 30, 2005
There is increasing concern that most current published research findings are false. The probability that a research claim is true may depend on study power and bias, the number of other studies on the same question, and, importantly, the ratio of true to no relationships among the relationships probed in each scientific field. In this framework, a research finding is less likely to be true when the studies conducted in a field are smaller; when effect sizes are smaller; when there is a greater number and lesser preselection of tested relationships; where there is greater flexibility in designs, definitions, outcomes, and analytical modes; when there is greater financial and other interest and prejudice; and when more teams are involved in a scientific field in chase of statistical significance. Simulations show that for most study designs and settings, it is more likely for a research claim to be false than true. Moreover, for many current scientific fields, claimed research findings may often be simply accurate measures of the prevailing bias. In this essay, I discuss the implications of these problems for the conduct and interpretation of research.
ScienceOpen Science Collaboration: Corresponding Author Bryan NosekAugust 28, 2015
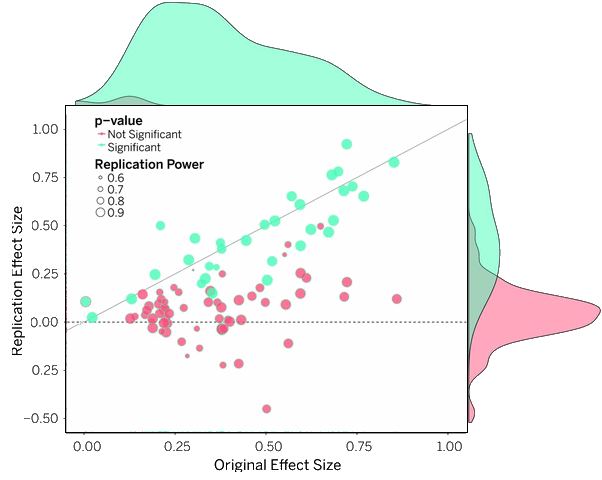
INTRODUCTION: Reproducibility is a defining feature of science, but the extent to which it characterizes current research is unknown. Scientific claims should not gain credence because of the status or authority of their originator but by the replicability of their supporting evidence. Even research of exemplary quality may have irreproducible empirical findings because of random or systematic error.RATIONALE: There is concern about the rate and predictors of reproducibility, but limited evidence. Potentially problematic practices include selective reporting, selective analysis, and insufficient specification of the conditions necessary or sufficient to obtain the results. Direct replication is the attempt to recreate the conditions believed sufficient for obtaining a previously observed finding and is the means of establishing reproducibility of a finding with new data. We conducted a large-scale, collaborative effort to obtain an initial estimate of the reproducibility of psychological science.RESULTS: We conducted replications of 100 experimental and correlational studies published in three psychology journals using high-powered designs and original materials when available. There is no single standard for evaluating replication success. Here, we evaluated reproducibility using significance and P values, effect sizes, subjective assessments of replication teams, and meta-analysis of effect sizes. The mean effect size [r] of the replication effects [Mr = 0.197, SD = 0.257] was half the magnitude of the mean effect size of the original effects [Mr = 0.403, SD = 0.188], representing a substantial decline. Ninety-seven percent of original studies had significant results [P < .05]. Thirty-six percent of replications had significant results; 47% of original effect sizes were in the 95% confidence interval of the replication effect size; 39% of effects were subjectively rated to have replicated the original result; and if no bias in original results is assumed, combining original and replication results left 68% with statistically significant effects. Correlational tests suggest that replication success was better predicted by the strength of original evidence than by characteristics of the original and replication teams.CONCLUSION: No single indicator sufficiently describes replication success, and the five indicators examined here are not the only ways to evaluate reproducibility. Nonetheless, collectively these results offer a clear conclusion: A large portion of replications produced weaker evidence for the original findings despite using materials provided by the original authors, review in advance for methodological fidelity, and high statistical power to detect the original effect sizes. Moreover, correlational evidence is consistent with the conclusion that variation in the strength of initial evidence [such as original P value] was more predictive of replication success than variation in the characteristics of the teams conducting the research [such as experience and expertise]. The latter factors certainly can influence replication success, but they did not appear to do so here…
by Denes Szucs, John PA Ioannidisdoi: http://dx.doi.org/10.1101/071530
We have empirically assessed the distribution of published effect sizes and estimated power by extracting more than 100,000 statistical records from about 10,000 cognitive neuroscience and psychology papers published during the past 5 years. The reported median effect size was d=0.93 [inter-quartile range: 0.64-1.46] for nominally statistically significant results and d=0.24 [0.11-0.42] for non-significant results. Median power to detect small, medium and large effects was 0.12, 0.44 and 0.73, reflecting no improvement through the past half-century. Power was lowest for cognitive neuroscience journals. 14% of papers reported some statistically significant results, although the respective F statistic and degrees of freedom proved that these were non-significant; p value errors positively correlated with journal impact factors. False report probability is likely to exceed 50% for the whole literature. In light of our findings the recently reported low replication success in psychology is realistic and worse performance may be expected for cognitive neuroscience.
http://www.nature.com/news/1-500-scientists-lift-the-lid-on-reproducibility-1.19970
http://michaelinzlicht.com/getting-better/
http://www.slate.com/articles/health_and_science/cover_story/2016/03/ego_depletion_an_influential_theory_in_psychology_may_have_just_been_debunked.html
You are probably familiar with this but I found them all of interest.
Mickey, glad to have you back.
I’ve been doing a far bit of historical research on the evolution of psychiatric research the early decades of the 20th century, in part to see if by going back to the beginning I might gain some perspective on why things are so stalled now. As background I have been steeped in a lot of recent work on measurement theory, largely the work of Joel Michell and Denny Borsboom (who is an academic descendant of De Groot’s legendary multidisciplinary research group in Amsterdam). This is way, way out of my typical areas of expertise (and much is way, way over my head, I’m sorry to say), but I’m getting the gist of things — I think.
One nagging issue that, for me, goes beyond discussions of research design or even statistical procedures (finding p-values, etc.) is this disturbing thought: there is no firm evidence that psychological attributes are truly measurable, though that is the assumption of ratings scales, psychological tests, etc. The assumption (particualrly in research based on the latent variables model theory of measurement, which dominates most psychological and psychiatric research) is the ontological status of an invisible underlying attribute that is (1) continuous and (2) quantifiable. This is an unproven metaphysical leap of faith, an inconvenient truth that no one wants to face directly. But to me, at least, it helps me understand why there is so little “progress” in psychiatric research. The stories coming out about the catastrophic experience by the DSM-5 Task Force and Work Groups and their failure in bringing about a paradigm shift based on dimensional rating scales just punctuates for me the real world consequences of not thinking through things clearly before “doing” science. Sociologist Owen Whooley has been publishing some fascinating research on this story.
I highly recommend the articles of Joel Michell, who writes clearly and bluntly on this issue. I am cursed with a natural attraction for iconoclasts who do not beat around the bush, so I very much appreciate his work. Denny Borsboom and his group in Amsterdam are also tackling this problem in a less directly iconoclastic way in the recent application of their work to psychiatry. There is one article by them in particular which I suspect may be viewed as a classic in the years to come because it indicates how decades of research on depression may mostly be invalid. A link to the article is on this webpage:
http://psychosystems.org/quiz-why-does-the-factor-structure-of-depression-scales-change-over-time/
I should have added a link to a provocative article by Joel Michell in which he answers his critics (Borsboom is one of them) and one directly challenging the emptiness of so much discourse by psychologists and psychiatrists about “hypothetical constructs:”
http://statmath.wu.ac.at/courses/r-se-mbr/dl/Michell_Psychometrics_Pathology_2008.pdf
file:///C:/Users/richa/Downloads/New+Ideas+Concepts+and+Measurement+2013%20(2).pdf
Richard, could I suggest that you keep a distinction between psychological ratings and psychiatric ratings? The metaphysical assumption of “the ontological status of an invisible underlying attribute” might be an issue in psychology (I am thinking of constructs like intelligence or extraversion) but it is not an issue when it comes to psychiatric syndromes. If I heard Max Hamilton say it once I heard him say a dozen times that his depression scale aimed to rate the burden of common symptoms in patients who already carried the clinical diagnosis of depressive disorder. He disavowed any intent at an essentialist characterization of depressive disorders, and he was especially harsh towards those who wanted to use the scale to make diagnoses – because the symptoms are all diagnostically nonspecific. Moreover, the symptom profiles among patients are pleomorphic.
Rather than adopt an essentialist approach, the Hamilton depression scale considered the burden of symptoms commonly seen in depressed patients. It did not matter whether those common symptoms were considered “core” features (like anhedonia, sadness, guilt feelings, suicidal ideas) or complications (like demoralization or incapacity or emergent anxiety/panic symptoms or emergent psychosis or suicide attempts) or epiphenomena (like fatigue and weight loss).
You linked to an article by my friend Eiko Fried, which you suggested “indicates how decades of research on depression may mostly be invalid.” I think that is an overstatement on your part. Fried and his colleagues reflected your position when they discussed that “(Depression scale) scores are used as a proxy for depression severity in cross-sectional research, and differences in sum-scores over time are taken to reflect changes in an underlying depression construct.” They went on to decry the lack of unidimensionality in factor analyses of depression scales. That would be a concern only for those who hold the essentialist position. Hamilton himself reported multiple factors in his own samples, as well as differences between men and women. For a clinical disorder, there is no reason to require unidimensionality, as we found in our factor analyses of patients with mania diagnoses. We found 5 independent factors that aligned with clinically recognized dimensions of manic episodes. That validation of clinical gestalt with statistical result is important for future work on the pathophysiology and the heterogeneity of manic episodes, especially mixed states that were emphasized a century ago by Kraepelin.
The second main point made by Eiko Fried and colleagues is that the factor structure changed over time. That was because they included post-treatment data, which skewed the distributions of rated symptoms. Figure 1 of their paper displays many sum scores well below what might be informative for an essentialist interpretation. The reduction of factors after treatment were just to be expected.
A further issue is that Fried and colleagues relied mainly on ratings from the widely criticized STAR*D study, for which validation of the enrolment diagnoses was not attempted, differential diagnosis was not emphasized, the attrition rate was near 50%, and concurrent psychotropic drugs were permitted in addition to antidepressants.
In the end, I would conclude that Fried and colleagues rejected the essentialist position and rediscovered the wheel that Hamilton described over 55 years ago. They concluded that depression scales provide what they term a “formative sum score” as opposed to a “reflective index.” When they say “the sum of symptoms certainly does provide some information about the general psychopathological burden people carry, and we can safely assume an inverse relation between the number of symptoms and the wellbeing of a person,” they could well have been quoting Max Hamilton. Elsewhere they added, “A formative sum-score, on the other hand, is nothing but an index: a sum of problems. These problems are not meant to reflect or indicate an underlying problem. Still, we can learn something from such a sum-score: the more problems people have, the worse they are probably doing in their lives.” Max could not have said it better.
Barney, thanks so much for the clarifications! This is your lifelong arena, not mine, and I defer to your expertise. The remark I made about decades of depression research being invalid comes from a bad paraphrase of a statement made on the “quiz” website link I added, which then allows access to the original article. Its the Borsboom’s group website. I did understand from the article, and of course from your comments, the point made in the article about reflective vs. formative variants of the latent variables model and their case for a formative sum score. That said, I think are are numerous rather important findings and interpretations in that article that did indeed get my wheels turning.
Back on line – barely. An old unfamiliar tiny notebook computer and no router. Sandra and Richard. Thanks for the links, Gives me something to read while I await a real computer [being built] and appropriate accoutrements.
Richard, nice to e-meet you, and I’m very glad you found the measurement depression paper you linked to above (that we describe in the ‘quiz’) interesting. It was quite a bit of work, and I will make sure for the next paper to ask Barney and hopefully also you to comment before we submit. Richard, I’ve been working on very similar things for a few years now, if there is other work you find interesting please let me know and I’d be happy to send you copies. I make all PDFs (including preprints) available here: http://eiko-fried.com/publications/
Barney, thanks for involving me in the discussion here. As you probably know I’m an avid reader here, but missed the comments section on this post.
As you may know I wrote my PhD on heterogeneity of depression, and problems revolving sum-scores of symptoms. You can guess how incredibly happy (and flabbergasted) I was when reading Hamilton’s 1960 paper in which he calls the sum score a “total crude score” and strongly advises against using it. Of course we would not consider his factor analytic techniques or sample sizes up to date, but the main message indeed is still valid half a century later. Sadly, most of this seems to have gone unnoticed (99.999% of all people using the HRSD do so using a sum score that they assume measures people’s underlying position on the unidimensional reflective latent variable ‘depression disease’).
The main points are:
– different depression symptoms differ in very important aspects, such as risk factors, biomarkers, impact on impairment, etc. Randolph Nesse was kind enough to offer his amazing support and expertise when I was working on these topics throughout my PhD.
– depression symptoms also interact with each other causally, and I’ve been very lucky to be able to work with Denny Borsboom and his great lab for a few years now (in fact I moved to Amsterdam just a few months back).
– Richard was kind enough to mention a blog post I wrote a while back on
factor structures. This may have many more implications than we can discuss here, and I am currently preparing a much larger paper on this (using the SCL-90 and 10 large datasets of people with all kinds of problems), but the main message really is that factors are likely not causal powers in the world, but merely descriptions and simplifications (we in psychometrics differentiate between reflective and formative latent variables). Sadly, this distinction is nearly never made in the clinical literature, and nearly all of my colleagues (even the smartest ones) simply assume that latent variables are always reflective in the realm of psychopathology. In fact, I recently wrote about this specific point in a blog post http://eiko-fried.com/common-problems-of-factors-models-in-psychopathology-research ).
Maybe I should highlight why I consider the blog post I linked to relevant. Here is a snippet:
“Authors, reviewers, editors: if both your model and your interpretation of psychopathology requires reflective latent variables to exist as real things in the universe that cause the covariance among your data, I would be happy to see a discussion about what these are. I am not saying they do not exist, but it is absolutely unclear to me what they should be, and we’ve been modeling these things for more than half a century now.”
Eiko, what a delight to hear from you. Along with Bernard Carroll’s responses, I feel I am getting some private tutoring from the best in the business. I hope that others will also find these technical issues interesting because they really are essential. Most clinicians and laypersons do indeed assume these latent variables are reflective and not formative. Many researchers do too because most folks do not feel the need to think deeply about the philosophical implications of their job — they just do it.
I think, too, for so many of us who are frustrated by the lack of significance progress in psychiatric research, we prefer not to be fully conscious of the point you made in your post directly above this one. We all naively want to believe that more than half a century of using latent variable models in psychiatric research has led to knowledge of the essential “reality” of the natural state of mental disorders. We ask ourselves: Aren’t medical researchers supposed to be studying “real” things? It boggles our minds when we begin to fully appreciate some of the finer nuances of the interpretation of latent variables in research.
And after more than half a century of this approach, very few clinicians or laypersons see the relevance of it because it has not led to breakthroughs in medical understanding or treatment. To many this sort of research all seems like a separate philosophical universe detached from reality, filled with “cute” discussions about whether underlying factors of “depression” really and truly naturally exist as objects of research or are constructed or formed by researchers.
Is there evidence of an iterative process in this type of research that has truly advanced the science of psychopathology at all in the past fifty-plus years? Or (just to keep playing the friendly devil’s advocate here) are all these publications claiming to find newer and better rating scales and factors nothing more that odd communiques from an irrelevant fairyland, a bit like the servants of the Glass Bead Game who live detached from the world in Castilia (to invoke a Hermann Hesse novel here)?
I ‘m not trying to be cute here, but I am indeed purposely being irreverent, because the average clinician and layperson has difficulty comprehending the relevance of this methodology in psychiatric research if it is not ultimately about “real things” that cause suffering in real people. Anyone want to launch a defense of why we should continue along a path that seems to have produced such little fruit? DSM-5 was almost based on it.
It’s come to the point that a psychiatrist will do more harm than good reading original research. I wonder what that implies about studying for recertification.
On Dr. Carroll’s and Noll’s point, Dr. Meehl and others have done some interesting work on “schizotaxia” and the concept of it as a latent variable.
http://bjp.rcpsych.org/content/178/40/s18
I think that’s when I began to realize something much less intellectually challenging. They had changed rating scales repeatedly after the study was in progress. And further, they had mixed these various scales as if they were interchangable – particularly the QIDS-C, the QIDS-SR, and the QIDS-telephone. Worse, the QIDS-C and QIDS-SR were collected in the same sitting. I gave up trying to untangle all of that because I decided it couldn’t ever be untangled. It took me a while to get the general point that changing horses in mid-stream was widespread in clinical trials, and generally invalidated the results. Even more remarkable to me, all that garbling of rating scales was right out in plain view in STAR*D, and nobody said much about it.
To relate that back to the discussion above which is at a much deeper level, STAR*D [and most of the clinical trial reporting] treats the score from a rating scales as if it measures a “thing” – “depression” as a noun. The scales are something else, an attempt to objectify the complexity of human subjective experience that is useful in comparative research if, and only if, they’re treated carefully. Multiple scales are used in a given study for cross validation, not to be mixed and matched at will. And the use of those scales in doctors’ waiting rooms pushes the genre beyond… well, just beyond.
And none of these have validity components as the MMPI-2 and PAI do.
A BDI score of 35 suggests depression, as score of 63 probably suggests something else.
As a researcher I would want to know if the subject is depressed but also if they have symptoms not even seen in clinical populations or if they are simply random responding.
Rating scales for signs and symptoms have a long history in psychiatry (I’m just now finishing up an article on this, so that’s why I’m sticking my neck out in these posts and risking the revelation of my profound ignorance on matters best left to Barney, Eiko and Mickey — so readers of this blog should pay more attention to them not me. In doing background research I have been amazed by how the implications of their very existence seem to go so unquestioned. Almost everything in psychiatric research pivots on them.
In what follows I’ll (quite easily) adopt the simpleton’s view from the groundlings’ section of the theater and try to describe what the last 50-plus years of the drama looks like from an outsider: One measurement theory after another has arisen and is debated, new and complex statistical methodologies are invented and tried out for test runs, all in an apparent collective effort to hold on to rating scales for dear life. The intellectual architecture of psychiatric research bends to them. The real world consequences of this became clear a few years ago when DSM-5 diagnosis would have been almost entirely dependent upon them if the clinicians in the APA had not voted down these proposals from the Task Force and Working Groups, which were comprised mostly of researchers.
Yes, of course, we know the advantages of having rating scales as opposed to diagnosing patients or selecting research subjects based on gut feelings. We seem to expect too much of rating scales, however. They are carrying too heavy a load. All of the comments above point out how little their limitations are understood by both clinicians and researchers, how they are routinely misinterpreted in the analysis of data, and how easily they slip our attention in descriptions of published research to the point (as Mickey pointed out) it is hard to tell how they are being used, or if they are being used honestly.As I noted, rating scales are the points on which so much research pivots, but they are so taken for granted that they have become invisible, regarded as imperfect but useful tools that can be created and re-created in a promiscuous fashion. Unfortunately, despite their importance, they are indeed often treated like garden tools that are interchangeable with dozens of other ones in the tool shed. For example, a book came out last year detailing some 120 psychotic symptoms rating scales that are used in research. They seem to multiply like Tribbles. Sometimes one gets the impression that some researchers think the solution to the obstacles in psychiatric research is the invention of a rating scale that would solve all problems. Perhaps there is indeed a Platonic realm where latent variables really do exist (perhaps even within individuals, which is not their assumed nature in psychiatric research where they mostly exist in the between-subjects “reality” of a population), and maybe, too an archetypal Ideal Rating Scale that the iterative flow of psychiatric research may be slouching toward. Will rating scales bring us closer to understanding psychopathology or have they outlived their usefulness?
I’m just raising these questions. I have no answers. I wish I did.
In the early 1960’s we were faced with a severe problem . Max Fink (Director of the almost unique Department of Experimental Psychiatry,)and I had reported on 180 imipramine treated inpatients at Hillside Hospita. This was a psychoanalytic establishment, where psychotherapy was the premier treatment. The patients were New York City indigent residents . At the time NYC picked up the entire cost ,regardless of length of treatment, at Hillside.The average length of stay. was 10 months.
Patients were referred for medication after some period of psychotherapy and concern was overcome about possible deleterious effects of medication on the transference, during continued psychotherapy .The reluctant decision that medication was needed was made by the clinical staff,that is,the supervisor.
Among those openly treated with imipramine a very intensive, longitudinal clinical study was initiated by the research staff– of the patient,therapist,supervisor and ward staff.. A clinical classification, based on drug effect, yielded 7 different behavioral patterns. For instance , considered was the pattern over time of drug management .Stopping imipramine and replacing by another agent, was considered good evidence of imipramine ineffectiveness.
On the whole 71% of these heterogeneous patients were estimated to benefit from imipramine.
After this two year Phase 2 ,we advanced to a late Phase 2 , double blind study of 168 heterogeneous patients , referred by clinical staff,randomized to imipramine,chlorpromazine or placebo.
Of these 143 (Placebo 43,Imipramine 52, Cpz 48 )yielded data for analysis .
Our outcome measures were the factorial derived Lorr scales. A,C E,F,G,K and Total used in the usual fashion,by,interview at baseline and after 4 to 6 weeks of treatment.
The point of this reminiscence is that none of these standard factorial scales, when used to compare IMI with Placebo, invalidated the null hypothesis . ..
This was embarrassing but stimulated critical thinking. These factor scales had been derived from a single occasion on a different sample. Further,some patient aspects might have received a high factor loading,but were irrelevant to a specific drug effect. If many such items loaded a particular factor the total could mask any specifically responsive items.
Therefore , the analysis was repeated for each item. That there should be a correction for multiple analyses was not the fashion then and in any case we were exploring.
Item effects ,sprinkled over the factors were evident. So status factors were methodologically suspect as change scores.
We were also led to think that the patients appearance at a single meeting yielded a small ,probably unrepresentative ,sample of usual behaviors. An intensive longitudinal clinical observation,in principle, led to a far more powerful evaluation of changes. So the longitudinal familiarity of the rater with the patient,across many different settings, ,while blind to treatment, was important with regard to precision. However cannot remember this variable used as a feature of good design.
Since then,the very procedure we viewed as a blunt instrument has become the standard procedure,made even more dicey by a statistical restriction to a single ,guessed,primary measure.
If somewhat irrelevant measures , restricted to single measurement occasions are status descriptions ,while different samples’ change measures depend on two such occasions , is there any reason to be surprised at unreproducibility? It certainly does not require the hypothesis that such measures are, in principle, unquantifiable. Nor do good reliability measures argue for adequate ,longitudinal, clinical description.
This measurement restriction re psychiatry seems largely due to the economics of NIMH and Pharma support.
References
1) Psychiatric reaction patterns to imipramine.
KLEIN DF, FINK M.
Am J Psychiatry. 1962 Nov;119:432-8.
. 2) MULTIPLE ITEM FACTORS AS CHANGE MEASURES IN PSYCHOPHARMACOLOGY.
KLEIN DF, FINK M.
Psychopharmacologia. 1963 Feb 22;4:43-52.
Well put, Richard. There is indeed a cottage industry of creating rating scales, and too little careful thought about their legitimate uses or their limitations. In clinical science, operationalism has its limits.
The goalpost shifting in STAR*D, noted by Dr. Nardo, is a serious misuse of the scales. Some workers like Per Bech have tried to distill the HAM-D down to an essentialist 6-item scale (but that has not been widely adopted). Stuart Montgomery and Marie Asberg introduced the MADRS as a scale designed to be sensitive to change… problem was they relied on data from just 35 patients to claim comparative advantage of the MADRS over the HAM-D on change, but that has not been confirmed.
Rating scales are just tools – they are not essentialist keys to distilled wisdom. Their chief pragmatic uses are in stratifying populations by severity and in tracking crude severity over time as a proxy measure of treatment effect. As Don Klein suggests, that proxy measure has been granted too much clinical validity as a stand-alone measure. One always wants to see concurrent or convergent validation of any inference drawn from changes in a rating score. That could be a self-rating to match a clinician rating, or vice-versa, or a global rating to match a summed score rating, and throw in an external measure of functioning as well. When such a cluster of measures yields convergent validation, then maybe the finding is important – but we rarely see that information in clinical trials reports.
As a footnote, a few years ago I surveyed the most highly cited papers in our field. Those with over 10,000 citations back then numbered 28 in all and 7 of those were rating scales. The remainder, too, were research tools – mostly statistical methods or analytic methods in pharmacology or biochemistry. The two top cited rating scales were the Mini Mental Status Examination (Folstein, Folstein, and McHugh) with over 33,000 cites back then and the HAM-D scale with over 16,000. Only 1 theoretical contribution (Albert Bandura) and one original discovery (Sal Moncada, nitric oxide physiology and pathophysiology) made the list with over 10,000 cites. Not a single Nobel prizewinner was among these authors. Clearly, in the citations game utility trumps original discovery or penetrating insight. And Richard is correct in saying the apparent utility may be illusory.
Whew! I survived Barney’s response. Here is a quote I think he may remember:
“Rating scales are not really suitable for exploring a new field of knowledge.”
Max Hamilton. “Editorial: The Role of Rating Scales in Psychiatry,” Psychological Medicine 6 (1976), 347.
“there is no firm evidence that psychological attributes are truly measurable, though that is the assumption of ratings scales, psychological tests, etc”
Wondering what you meant by this.
General intelligence is measurable, as is dementia rating, and the deltas are important in clinical assessment. Certainly there are people who are more extroverted or conscientious than others, even though the measurement of operational concepts will never be perfect.
I have found that the Five Factor Personality actually conforms pretty well with observation.
Unbelievably I have had arguments with physicians who insist that physicians are no more intelligent or conscientious than the population as a whole. Even after I show them this:
https://images.duckduckgo.com/iu/?u=http%3A%2F%2Fwww.iqcomparisonsite.com%2FImages%2FOccsX.jpg&f=1
Paul Meehl was mentioned – this excellent article about strategies in science from 2004 might interest. “Falsification and the protective belt surrounding entity-postulating theories” – ABSTRACT: Meehl’s article is a contradiction. In every area, he recognizes some of what is wrong and then advocates a course that will produce more of the same. He sees the problem with falsification and in essence advocates for its alternative, verification, but falsely claims this strategy is still falsification and is useful when there is a loose link between theories and their auxiliaries and conditions. He acknowledges the proven value of tightening the link between theories and their auxiliaries and conditions, but rejects that course because it does not apply to his preferred theories. Twenty-five years later there is even more “slow progress” to ponder. It is time to dismantle the protective belt surrounding entity-postulating theories that Meehl’s reasoning has helped to create. – ON RESEARCHGATE HERE https://www.researchgate.net/publication/240194476_Falsification_and_the_protective_belt_surrounding_entity-postulating_theories , FULL ARTICLE GOOGLE-ABLE 🙂
I see the problem as self-report inventories more than quant psych in general. Clearly tests to measure operational concepts should include validation items. Me too self-report inventories are a scourge as much as me too SSRIs, but I have trouble accepting that difficult or inexact measurement is the same as meaningless. Certainly one cannot fake an IQ result of 140 (unless they know the answers in advance). I concede that someone might fake extroversion on a 5FP if they were trying to get a sales job. I’d like to think suicidal ideation, which is harder to measure, is taken seriously before the objective proof arrives. I’m mystified why the 2 scale of the MMPI-2 or the DEP scale of the PAI is not used since fake good or fake bad is screened out.
Dr. O’Brien, on the point about quantification and psychological attributes, I’ll refer you directly to the work of Joel Michell. I provided two links earlier to articles that outline his argument, but its historical background is detailed in his book, Measurement in Psychology: A Critical History of a Methodological Concept (Cambridge University Press, 1999).
Thanks to all for such a valuable discussion. A question for Drs. Carroll and Nardo- in earlier posts, I had the sense that while you appreciated the heterogeneity of depression, that you did seem to take what appeared to be an essentialist position on melancholic depression ( and Schizophrenia, perhaps). Did I misunderstand?
Sandra,
I do think of Melancholia as an entity and the classic late adolescent onset Schizophrenia as a “probable”…
In his book, The Metaphysics of Psychopathology, Peyer Zachar discusses the human psychological pull towards essentialism. I believe that is an important contribution to this discussion. It is hard, once things are named, to not think of them as “real” things rather than constructs. So our rating scales reinforce essentialist notions even if their creators had other intentions. We almost can’t help ourselves. He says it better, of course.
https://mitpress.mit.edu/books/metaphysics-psychopathology
Dr. Noll,
I did read it and I think his standard is unrealistic, making mathematically perfect the enemy of the good. Certainly, on a practical level, we could not even talk about conditions such as dementia intelligently without some form of measurement. I do appreciate what he is trying to say though but his core argument is Szasz with equations.
Sandra, I do think of melancholia as a distinctive descriptive syndrome, but that does not imply an essentialist view of melancholia. Consider the differential diagnosis of melancholic depression from look-alike conditions such as adjustment disorder with depressed mood. Cases can have considerable overlap of symptoms but we readily recognize the classic presentations of each. It’s the large ambiguous group that causes the nosologic debates, as in the Newcastle-Maudsley arguments of the 1960s – 1970s. DSM-III didn’t resolve those issues, it just swept them under the rug. Coming from his biometrics background, Spitzer was preoccupied with casewise uncertainty to the point where he disregarded clear syndromal distinctions. That’s how we ended up with generic major depression.
In addition, within the melancholic group there is heterogeneity. First there is the heterogeneity of unipolar and bipolar course of illness among patients with melancholia diagnoses. Setting that aside, there is still much heterogeneity, notably those with a positive family history and an early onset versus those with a late onset and a negative family history, who nowadays are diagnosed as suffering from vascular melancholic depression. They represent the majority of the case load in many ECT services.
This formulation suggests a common proximal pathophysiology driven by differing distal causes – genetic/developmental versus vascular in the case of unipolar melancholia. But proposing a common proximal pathophysiology is not an essentialist position.
I come back to comparisons of melancholia with Parkinson’s disease, where there is a classic syndrome plus several look-alike disorders. In the early stages there is often diagnostic uncertainty between PD and essential tremor – but that casewise uncertainty doesn’t require neurologists to declare that there is just generic tremor disorder, as Spitzer did for depression. Meanwhile, our neurology brethren are doing exceptional work unraveling the multiple pathways to what used to be regarded as the unitary syndrome of PD. Oh, and another lesson we could learn from the neurologists is diagnostic restraint – they don’t allow a diagnosis of PD with less than 2 years of observation and without a therapeutic trial of levodopa.
Dr. Mickey mentioned classic late adolescent onset schizophrenia as a probable candidate for an essentialist view. Here again, I would say there is good reason to call that a distinctive syndrome (we sometimes used to call it hebephrenia) but at the same time we can recognize that there are multiple distal causes of the presumed common proximal pathophysiology (genes, embryonic malnutrition, maternal infection during embryogenesis).
Thank you, Drs. Carroll and Nardo.
Eiko Fried kindly supplied us with links to his webpages above. I have been reading through his articles and blogs and am appreciating the way in which his work is shining a light on rating scales for depression — their remarkable divergences in content, their uses and misuses, and their history. There is a half-dozen or so first created in the 1960s and 1970s (out of 280 created since 1918) that are used in the majority of published depression research studies. This familiar human tendency toward “path dependence” can contribute to the reluctance for critical re-examination of assumptions underlying these tools.
For those who may not feel quite ready yet to plow through the scientific literature, I can strongly recommend they take an hour out of their day and watch Eiko in action in the video of a talk he gave at Arizona State in 2015 which summarizes and explains the work he mentioned in a post above. Eiko is not only super-smart but charismatic, a natural teacher. I hope he is destined for hosting his own PBS television series one day!
Here’s the page, link at the bottom:
http://eiko-fried.com/presentations/
I still want to ask the broad question to the members of this electronic seminar that I raised above:
Is there evidence of an iterative process in this type of research that has truly advanced the science of psychopathology at all in the past fifty-plus years?
Will a shift to an epistemological view of latent variables from reflective to formative, and describing in networks in which it appears they bear causal relationships to one another, lead to translatable advances in medical research in psychopathology?
Or (being the friendly devil’s advocate here, and looking at this with the wide angle lens of a historian), is Symtomics merely a symphonic movement to the next level of the Glass Bead Game by the monastic community of Castilia?
I’m posing these questions as a sincere clinician and historian who, like so many of us, are looking for an Ariadne’s thread out of the maze.
Missing the words “signs and symptoms” after “describing” in the first question, making it “describing signs and symptoms in networks… .” — apologies. Also, Hesse wrote about Castalia, not Castilia.
I reviewed his 2015 PPT. Not much I disagree with in terms of most depressions (though I agree with Dr. Carroll that full blown melancholia is categorical not dimensional). If you follow the logic of network model, then clinically the implication would be that it is important to treat insomnia very aggressively (but not necessarily with benzos and Z drugs) and early to break the process leading to multiple symptoms. I find this correlates with clinical experience.
The other implication is that the network model bolsters my earlier argument about the MMPI-2 and the PAI being better instruments for research since these instruments are more contextual.
I think we can all agree it’s time for a moratorium on any more self-report inventories (I still laugh at the claim that the PHQ-9 was “developed” with a grant), especially those that include a lot of somatic symptoms in demographics were a lot of somatic symptoms are going to be present anyway.
Just a quick response to Dr. O’Brien before I rush off to teach two classes to undergraduates: Do we need confirmation from a complex statistical model of networks to confirm what traditional physicians like Hippocrates and Galen would have noticed and recommended centuries ago, that getting regular, good sleep is a healthy thing and prevents all manner of health problems?
In the context of this discussion I would like to query the participants about skill #1 here:
http://www.jaacap.com/pb/assets/raw/Health%20Advance/journals/jaac/Article%203.pdf
(Page 10 in the article, page 2 on the pdf)
Specifically: are there easy to digest references (i.e. Aimed at those other than the choir) that can help rally CAPs to more strongly question the approach being championed in that article? I cannot emphasize enough how strongly the approach in that article is being pushed. And, how little individual CAP “opinion” is effective in pushing back.
Whatever the flaws of the current journal based system for vetting knowledge it remains the main game in town. There’s are reasons that the 329 RIAT team made such an effort to get the publication into the listerature and into the BMJ. There are reasons that Goldacre and others continue to engage the literature, especially high profile journals, in their crusades. What parallel process is going on to address articles like the one linked to above?
It is jarring to read the sophistication of thought in this thread alongside the presentation in the article linked to above.
I was speaking with a student the other day and trying to explain why they might not wish to train to become a CAP given our future. Had some trouble articulating why. They are particularly drawn to working/interacting WITH children and developing a sophisticated understanding of those individuals. Perhaps I will print out that JAACAP article for them so they can better understand the kind of metric based skills that will be expected of them. So they can better understand what, aside from all the lip service, what will be tail and what will be dog.
Response to Dr. Noll,
Of course not.
In the clinic, the standard is verisimilitude whether derived from data or common sense or experience.
In earlier comments I have always maintained that sleep hygiene, moderate exercise and psychotherapy should be used first for mild depression before drugs.
The issue with MDD is sometimes that sleep hygiene alone isn’t enough and that some sleep restoration is necessary to break the vicious cycle. His model actually supports that clinical impression.
My major issue with some of the references is that psychiatry will never be ophthalmology, though I agree we should certainly try to be more like ophthalmology. I have certainly been a vociferous critic of DSM-5 (Mood Disorder not Otherwise Specified??? A category for a noncategory!). Even in 200 years, I don’t think a “schizotaxic marker” will be as accurate as a refractive error measurement.
Like many here, I don’t believe that there are 300 distinct psychiatric diagnoses, but about fifteen that are constructionally valid. So I’m basically a nosological moderate between the extremes of DSM and Szasz.
Dr. Noll, On a tangent: In your historical explorations have you come across a good academic reference that speaks to these very long term psychiatric sequelae in children:
https://vanwinkles.com/history-of-sleepy-sickness-encephalitis-lethargica
Especially one perhaps written in a less dramatic style?
Some thoughts on comments in this thread by James O’Brien:
My reading of Paul Meehl’s construct of schizotaxia, especially as reformulated by Steven Faraone and Ming Tsuang, is that it’s a forme fruste of the clinical disorder, often observed in the families of clinical cases with schizophrenia diagnoses.
“And none of these rating scales) have validity components as the MMPI-2 and PAI do.” That’s true, but its importance will depend on context. If the patient already has a settled clinical diagnosis then observer ratings don’t need validity components (like checks on response bias). Self-ratings are more vulnerable to response bias. When we compared the HAM-D against the Carroll Depression Scale (a self-rated version of the HAM-D) we saw good agreement except in 2 situations. Patients with non-melancholia depression diagnoses scores higher than the HAM-D on their self-ratings, while patients with severe melancholic depressions scored lower.
“I have trouble accepting that difficult or inexact measurement is the same as meaningless…. (don’t make) mathematically perfect the enemy of the good.” I quite agree. That kind of obsessoid paralysis has its roots in an essentialist position. Remember, they’re just tools. I loved your expression Szasz with equations.
1boringyoungman,
I know books have come out on the encehpalitis lethargica episode in recent years, but I have not read them. A quick Amazon search should locate those for you. It is a topic I have been meaning to explore since it is a phenomenon that falls within the historical period in American medicine and psychiatry that I research (1880 to 1940). With the recent passing of historian Gerald Grob, a man of great generosity of spirit, and with younger generations of historians of psychiatry who (naturally) have an interest in the post-1950 decades which most immediately preceded their own births and shaped the era they grew up in, there are only a few of us out here like me who have a soft spot for American alienists, neurologists and psychiatrists from a century ago. My interests follow the thread of psychosis throughout history.
What a great comments section this is turning into.
I very much agree that the problem is research methodology in general and not pharma-specific. As I have said before, archangels with not conflicts of interest would have trouble doing good psychiatry (or general medical) research under the current standards. The fact that replication is so poor for oncology certainly implies it is even worse for psych.
I’m a psychotherapist with a nerdy research side, and I just want to offer up huge thank yous to all of you for this engrossing discussion and to our resident (not-so)boring old man for hosting the space and sparking the ongoing conversation from the sweat of his free labor. I have nothing of substance to contribute for the moment, just gratitude for the scope and relevance of the experience represented by these voices here.
As a therapist I face daily the challenges of talking about things we don’t really “know” — trying to offer useful information to clients without suggesting that we understand any of this better than we do.
The odd comfort of so much of the science being wonky is that I’m forced back on the art of the clinical encounter and living with the humility that I sometimes help people even if I don’t fully understand what it was that worked. It’s not exactly bone-setting, but it has its rewards.
I hope you all will keep up the discussion!
Dr. Carroll can you please provide a link to your research about the correlations between the HAM-D and the Carroll Depression Rating Scale? I ask because the usual finding in psychiatric and psychological (personality) testing is that the correlations between self-report and observer ratings are quite low. You seem to indicate that you obtained “good’ correspondence between the HAM-D and your rating scale.
Sure, Tom. Here are the principal articles from 1981, with links.
I should say that after I retired I licensed the CDS to Multi Health Systems in order to dispense with the task of sending out copies that folks requested, and also to ensure that someone would ride herd on any unauthorized, mutant versions that might spring up, as indeed happened with the HAM-D. For this I receive an annual royalty, which is de minimis. Indeed, for almost 30 years while I had institutional support I gave the scale to colleagues at no cost to them.
Carroll, B.J., Feinberg, M., Smouse, P.E., Rawson, S. and Greden, J.F.
The Carroll rating scale for depression. I. Development, reliability and validation. British Journal of Psychiatry, 1981; 138: 194-200.
http://tinyurl.com/hk5cneg
Smouse, P., Feinberg, M., Carroll, B.J., Park, M. and Rawson, S.
The Carroll rating scale for depression. II. Factor analyses of the feature profiles. British Journal of Psychiatry, 1981; 138: 201-204.
http://tinyurl.com/hfcb3mr
Feinberg, M., Carroll, B.J., Smouse, P. and Rawson, S.
The Carroll rating scale for depression. III. Comparison with other rating instruments. British Journal of Psychiatry, 1981; 138: 205-209.
http://tinyurl.com/gnhmv6o
Merci beaucoup Dr. C.
Oh my, you wrote a whole book full of insightful and constructive comments and links to references here! 😉 And even after 50+ comments this hasn’t turned into what usually happens to discussions on the internet … I will definitely drop by more regularly.
I’ll try to address a few points that stand out to me. For most things though, I’ll have to really learn from the much more experienced folks here (for instance I still haven’t found the time to read Meehl in the detail he deserves).
1. Rating scales
1A) Many scales are used, and as Dr Noll mentioned, there are over 280 scales for depression out there today. In a recent paper, I analyzed 7 commonly used scales, and find 52 distinct depression symptoms. This not only underscores the heterogeneity of depression (and the difficulty of anybody trying to find biomarkers or risk factors *for depression*), but also shows that different scales will lead to different research outcomes. I link the paper here because I’m about to submit the final revision, and any comments are very much appreciated. I am sure you can tell from the paper that I care about this issue, but am way too young to really have a proper understanding of the history and development of all these scales, which is why working with Randolph Nesse on many prior projects was extremely insightful. (https://osf.io/azqw9/)
1B) Per Bech and the HRSD-6 were mentioned a few times. This is a bit of a trigger topic for me, because researchers have started using responsiveness of scales as a psychometric quality: if patients respond more to treatment on scale 1, this means the scale is superior than scale 2. Per Bech has stated that explicitly in a number of papers actually. This reasoning upset me so much that I wrote a constructive, but critical review for a recent study, and I was very lucky that the Editor liked the review and invited me to publish it as a commentary. In sum, if your scale does not measure relevant problems of patients, i.e. has limited content validity, then it is not a better scale even if patients ‘improve more’.
1C) Barney mentioned that rating scale papers are well cited. I checked recently, among the top 100 papers ever published in all Sciences 3!!! were rating scales of depression: Hamilton Rating Scale for Depression (HRSD; rank 51) (Hamilton, 1960), the Beck Depression Inventory (BDI; rank 53) (Beck et al., 1961), and the Center of Epidemiological Scales (CES-D; rank 54) (Radloff, 1977).
2. Reliability of measurement
Donald Klein wrote: “We were also led to think that the patients appearance at a single meeting yielded a small , probably unrepresentative ,sample of usual behaviors. An intensive longitudinal clinical observation,in principle, led to a far more powerful evaluation of changes.“
This is extremely interesting! I had not been aware of the references, this is incredible insightful, thank you for sharing. Could you send the papers to eiko.fried@gmail.com? I am unable to find PDF versions.
Recently, people have started to measure psychopathology 5-10 times per day, for a few weeks, to construct time-series networks. Here is an example of a study with only 1 measurement point per day by the brilliant Laura Bringmann, which looks at the BDI network of patients: http://journals.cambridge.org/action/displayAbstract?fromPage=online&aid=9546895&fileId=S0033291714001809
Using multiple measurements, one may be able to deal a bit better with measurement error. However, of course, these are self-reports, which leads to other problems.
3. Network models & idiographic aspects of psychopathology
I lack clinical experience, but James OBrien mentioned that the prediction from network studies that treating the most central symptom insomnia will lead to improvements corresponds to clinical experience. This is super interesting, and the next step is now empirically to try to find out whether that is the case. The coolest thing is that we can now get personalized networks for each patient (after 2-3 weeks of measuring daily). It’s an open question how reliable these networks are, and there are a number of challenges with the estimation of networks (happy to share papers if you’re interested), but overall this leads to a idiographic shift that many people like Peter Molenaar have talked about for so long (Aaron Fisher and his lab have also written about this). I see this as a potential way around the heterogeneity of the depressive syndrome: evidence based treatment of individuals.
Richard Noll mentioned here: “Do we need confirmation from a complex statistical model of networks to confirm what traditional physicians like Hippocrates and Galen would have noticed and recommended centuries ago, that getting regular, good sleep is a healthy thing and prevents all manner of health problems?”
I think the point is more that in some people, insomnia may lead to fatigue and it stops there, but in others, the same amount of insomnia leads to fatigue -> concentration problems -> psychomotor problems -> marital problems -> suicidal ideation. And it would be great to figure out how and why.
Thanks for this super interesting discussion!
Eiko,
Good stuff. I look forward to the future between-subjects AND within-subjects descriptions of psychosis from this new network model perspective. As you and others have noted, we don’t know yet how/if networks modeled from n=1 time series studies relate to between-subjects network models (which is what your beautiful charts reflect in your publications — clinicians should not look at them and evoke a mental image of those charts when assessing an individual patient — at least not yet)..
Before this interesting new line of research takes flight, I do want to express my queasiness about one thing: those darn ratings scales, and how they were selected and used in the creation of those large data sets that statisticians have to dip into to pump blood in the veins of their models. Your own work on the assumptions and use of depression rating scales is, to me, quite important. They are terrific critiques. I know you are aware of the problem with respect to the data sets that you must rely upon.
In the network model, the assumption that symptoms are independent of one another and are engaged in causal relationships with one another in a network “representation” is of course intriguing and corresponds to some aspects of clinical experience, at least for some of the initial symptoms in the causal network. I am hoping young brilliant minds who engage in this line of work can come up with something new to straighten out the mess in the literature on “psychosis-proneness.” I can already see the relevance of this model to heterogeneous conditions such as “depression,” and I am hoping it can also be fruitfully applied to psychosis.
Due of course to my own ignorance, the depths of which I am sadly aware of, I cannot shake the impression (intuition?) that the network modeling discourse in psychiatric research may remain a Glass Bead Game. Perhaps your network modeling colleagues will even immortalize my malaise by dubbing it “Noll’s Glass Bead Game Reservation” to this new field (any help in pumping up my citation count on Google Scholar is much appreciated). I just want to be on record for voicing the concerns of “the little guy” — we clinicians and historians who seek better n=1 clinical diagnosis and treatment in actual practice in quotidian reality and who are tempted to historicize seemingly novel turning points in psychiatric research. The wheel of history does seemsto be turning in this corner of psychiatric research. We all hope for genuine movement as well.
Just sayin’!
Someone sent an email to me asking me to elaborate on the Glass Bead Game. I of course suggested reading Hermann Hesse’s long novel (which led to his Nobel Prize in Literature), the Wikipedia entry (of course) and this short appreciation by a writer who re-read the novel later in adulthood and came to a new realization of its meaning:
https://theamericanscholar.org/herman-hesses-the-glass-bead-game/#.V8mbS_krKUk
Thank you Dr. Noll
Who wouldn’t agree with the usefulness of syndromes as peculiar and reliable clusters of symptoms with different diseases-known and unknown yet- possibly producing any syndrome except anti-psychiatrists who reject any label and medical diagnoses ?
On the other hand, using Parkinson’s disease versus Parkinson’s syndromes as a model for psychiatry is biased by the fact that neuro-psychiatry had been divided according to wether or not some clear brain disease was present and localized to some part of the brain.
Any good neurologist can bet with accuracy to a precise brain localization after only a thorough clinical examination and interrogation. Only the best of them resist the temptation to consider than any complaint that can’t be given a proper diagnostic- be it a syndrome or a disease diagnostic- is to be considered a psychiatrist’s problem.
This critic of one of Dr. Carrol ‘s thoughtful arguments doesn’t mean that I am foolish enough to consider that syndromes don’t exist in psychiatry and that the same clinical picture and history of illness can’t be produced by several different clear-cut diseases to be discovered. My point is that without the neurologists ‘ability to define syndromes by anatomical localizations of diseases in brain, nerves or muscles, it might have been unfortunate that psychoanalysis made psychopathology of the old continental traditions disappears from the research and diagnostic criteria without going back to it when the excesses of psychoanalysis made it a nuisance to be replaced as the main way of thinking mental illnesses and their diagnosis from the DSM3. Even those expecting much of genetic studies had to give up any hope of genetic variations easily translated in psychiatry syndromes
Ivana, I think even the neurologists will attest that they cannot in fact always “bet with accuracy to a precise brain localization after only a thorough clinical examination and interrogation.” Think multiple sclerosis or nonlocalizing frontal lobe tumors. As for Parkinson’s Disease, it was recognized, like melancholia, in ancient times, and almost 150 years elapsed from James Parkinson’s classic description until there was any definite identification of specific pathology. Yet during those 150 years physicians did not seriously doubt that there would be found an underlying pathophysiology. The deconstruction of Parkinson’s Disease into the classic syndrome and the look-alike syndromes came much later. The syndromal status of PD for 150 years did not rest on our recognizing degeneration of dopamine-containing cells in the substantia nigra – that was just the final step. The totality of the clinical evidence confirmed the salience of the syndrome. Likewise, the clinical validity of the A-list psychiatric disorders rests on converging evidence from many directions, and psychiatry doesn’t need to apologize for that.
I’ll make this observation…that in thirty years of doing forensic psychiatry, the impact of a witness or defendant or claimant telling a blatant lie is far less than it used to be with judges and juries. Attorneys in general have made the same observation. It used to be if someone was caught in a lie, it was game over, now there is a lot of excusing. The Brian Williams case was a perfect example of something that would have been an absolute career ender thirty years ago. This is a huge problem also in academia…a perfect example would be Jonathan Gruber of MIT being caught red handed bragging about his deception on the ACA, yet nothing happened to him after the initial firestorm.
In the 5FP model, one can say that agreeableness has supplanted conscientiousness and openness as the most treasured personality value among the elite. This has certainly served them well for example in the relationship between politicians, charitable foundations and lobbyists. Also, obviously, pharma and KOLs. We often see the Church Ladies of the APA reminding us to be agreeable even in the face of obvious KOL COI or fraud. The rationalization of the Affair de Kupfer was a perfect example of agreeableness taking precedence over conscientiousness, or truth as a core value. Meehl observed this thirty years ago as a problem in case conferences that obfuscated an enlightened search for the truth.
Openness is far from a core value as central planners in research and the grant game favor rigid approaches (more and more “me too” drugs) and discourage thinking outside the box. The lack of openness has much to do with the inability to change academic research attitudes that fail to replicate findings.
Alexander Pope admonished that critics should be constructive in their comments since they can do more damage to art than bad artists. I’m not sure that applies to science when the problem is with a failed system rather than mere individual cases of bad science divorced from those influences. I think with the amount of bad science we are really at the point that we have to blow up the village to save it.
So it has evolved that institutional and academic psychiatry and academia have placed a high value on agreeableness and lessened conscientiousness and openness. Like Meehl, I think agreeableness is overrated and a crutch for the insecure. To paraphrase Churchill, the establishment has all the virtues I despise and none of the vices I admire.
@ James OBrien, I was temped above to write something about B5 personality but did not, for the sake of not side-tracking the discussion. But I think it fits well here now.
First, the B5 actually do often not fit data well if you’re not trying to find them. If you fairly fit also 4 and 6 class solutions, 5 factors will rarely be recovered.
Second, you argue that the B5 are useful –– and I couldn’t agree more. That is exactly how we should understand latent variables in psychology: as useful simplifications of the world that allow us to make important predictions.
Third, however, this does not mean that the B5 are something that exist as essentialist kinds in the Universe, the same way “primary emotions” or “mental dsiorders” do not exist as essentialist entities –– they are not reflective latent variables. They are formative latent variables, they are summary statistics, they are things we made up to simplify and describe human behavior. That works for me. And because things are formative does not mean they cannot be useful, of course. SES, the prime example for a formative latent variable, is highly predictive of morbidity and mortality –– it is highly useful –– although we do not have to posit it exists in the universe as a true thing.
Bernard,
We shall agree to agree on the usefulness of syndromes even in psychiatry and I have been known to make use of Parkinson’s syndrome myself to try and explain to anti-psychiatrists or psychoanalysts what a syndrome is vs definite illnesses of known causation.I prefer to use the type1 diabetis killer described by the Ancient Egyptians when it comes to be competent in describing i.e. discovering the existence of a true illness on clinical symptoms only thousands years before any biological understanding of how and why extreme thirst & producing high volumes of sugary tasting urines was a death sentence without insuline treatment.
My point was precisely that by forgetting about the continental European tradition of psychopathology trying to describe in depth what makes some kind of patient different from another kind, there is little hope to advance and find valid syndromes in psychiatry. I don’t want to offend anyone but if MDD is mixing apples and bananas plus a few inedible leaves, there is no logical way of expecting any better use of MDD scales will solve the problem.
PS:
I remember fondly a panel of academics at a EPA meeting a few years back admitting unanymously that they never used any MDM scale in clinical practice when not using the patient in a research protocol.
By the way, 1919 is the time of localization of Parkinson’s disease In the human brain, quite a few decades before psychiatry separated from neurology. In 1968 in France:
https://en.m.wikipedia.org/wiki/Konstantin_Tretiakoff
Bernard,
I forgot to answer about localizing multiple sclerosis or “non localizing frontal tumor. I am not a neurologist and my 6 semesters of neurology and one of neurosurgery as a resident happened in the eighties but It doesn’t seem to me easy for someone suffering from conversion disorder or any fraudster to receive from a good neurologist a multiple sclerosis diagnosis unless the person would pretend to be in full remission without any symptom and could describe perfectly coherent neurological localizations in the past. About brain tumors of course those tumors growing slowly would remain silent for a long time and some locations will give symptoms more rapidly than others. Of course, some false localizing of tumors can occur clinically if the tumor is producing sane brain part to suffer compression or cranial nerves to be compressed or strained. And some tumors first sign an epilepsy but even then , good neurologists won’t hesitate at localizing a cerebral hemisphere problem.
Sorry 3 semesters of neurology and one of neuro-surgery.
Dr Nardo,
On what I understand to be the main subject of your post , Pr Keith Laws is worth some,admiration for the bravery of this British academic psychologist debunking psychologists pitiful science and conflicts of interest.
The best introduction to his work and his worth seems to me one of his blogposts called “Science is other correcting”. It is how it should work but it takes a lot of bravery to fight powerful CBT talking therapists having the current fashion and the power in committees like the NICE going for them.
http://keithsneuroblog.blogspot.fr/2016/01/science-is-other-correcting.html
Ivana, Yes, Type 1 diabetes works equally well as an example of syndrome recognition long in advance of knowledge of pathophysiology. And we are absolutely on the same page about the heterogeneity of “major depression.” It has been a disaster for incisive advances in research on depressive disorders.
As for using rating scales in clinical practice, my experience was that they are quite useful if done unobtrusively. I committed the HAM-D to memory during my residency and I would be sure to cover the items during interviews with depressed patients, then complete the form after the interview. The longitudinal data were always clinically useful – for picking up recurrences early and for clarifying the nature of residual symptoms. That was how the light bulb went on for me about the antidepressant property of lithium. One of my patients, known to be bipolar, told me that lithium helped him but only by relieving the psychic pain component of his depression, without modifying his anhedonia and lassitude. He reported, “I feel OK, Doc… I am not hurting but I am not getting anything done… Usually when I come out of a depression I get busy on all the stuff that has been neglected, but not this time.” That state persisted for several weeks. When I then added imipramine he rapidly came the rest of the way back to full recovery. The symptom ratings during this period confirmed the differential effect of lithium on depressive symptoms. My experience with this patient was an important key to the formulation of what is called the Carroll-Klein model of mood disorders – yes, it’s that Donald Klein, who taught us all so much.
Thanks also for the reference to Tretiakoff’s work in Parkinson’s Disease. Tretiakoff was an important early investigator but the story didn’t really come together for the pathophysiology of PD until the 1950s – culminating in the first trials of levodopa in 1960. Here is a good historical account.
I agree. Just like orange green and purple are not primary colors, they are still useful as descriptors. It is far more accurate to say that conscientiousness (which may have components of neuroticism) exists and some people are more conscientious but it is difficult to quantify than to say the concept is invalid and we shouldn’t even bother talking about it.
Dr OBrien,
I understand you weren’t probably answering to me but just in case:
My point concerned psychopathology in the European tradition definition of the term more broadly defined than Jasper’s body of work.
It means that instead of worrying about quantification, and as far as diagnosis is concerned, it’s the peculiar quality of the experiences that count.
Of course, it has already be told in this discussion that Hamilton didn’t pretend to any diagnosis scale but even as a follow up tool, to assess the disappearance of peculiar thoughts of a special quality is of the utmost interest for those Interested in psychopathology in XXI c. I know of an Italian school based in Florence with pupils in Norway I think and of the Danish school which was created by one late single psychiatrist.
Those psychopathologists have nothing , to the best of my knowledge, to do with the lucrative Open Dialogue business supposed to have worked wonderfully in an isolated district of Northern Finland which is more authoritative social psychiatry making anyone mental illness an issue for his family and neighbors to know and interfere about if I understood correctly.
That can’t happen here in the era of HIPAA. It also shouldn’t. It’s public stigmatizing and the therapeutic state even if we pretend it’s all in the spirit of Burning Man and I can think of a hundred things that can go wrong.