So, picking up from explanation would be welcome… and looking at the enrollments in RAP-MD-01, RAP-MD-02, and RAP-MD-03 that seem so high in those Rapastinel Clinical Trials. The way trialists pick their sample size is to do a Power Analysis. Using the Standard Deviation from a previous similar study, then pick the difference in means between the control and experimental values you would consider meaningful, and it spits out a sample size. Here’s the formula:

These studies use Montgomery-Asberg Depression Rating Scale [MADRS], and I can’t find any data to give me a Standard Deviation for Rapastinel using MADRS, nor do I know that scale well enough to select a mean difference. But, if you’ll allow me a bit of numeric mojo, I can use the Z Scores for p=0.05 and an 80% power [both standard], si I simplified the equation. I noticed that it has a clause that contains the formula for the Cohen’s d Effect Size so I substituted and come up with a formula that calculates the sample size for the group for any given Effect Size [could that be right?]. The table on the right gives some example values:
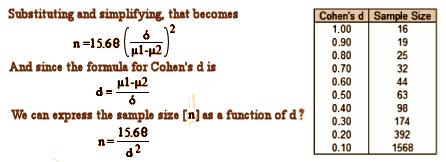
Looking at the group sample sizes for RAP-MD-01, RAP-MD-02, and RAP-MD-03, we have 700÷2 = 350, 2333÷3 = 778, and 1556÷2 = 778 respectively. Applying the formula, that gives Cohen’s d values of 0.21, 0.14, and 0.14. So if my formula works, using Cohen’s rough guidance [0.25 is a weak Effect, 0.50 is moderate Effect, and 0.75+ is a strong Effect] these studies are powered to detect statistically significant differences at Effect Sizes that are for all intents and purposes no Effect at all, clinically insignificant. By this read, these studies are dramatically overpowered.
And as to the question, why three different clinical trials that are close to identical? That one’s easy. They need two statistically significant RCTs to be eligible for an FDA Approval. Instead of doing a trial, and if it’s positive, trying to replicate it, they are doing them simultaneously because it’s faster. Sinilarly, why so many sites? I really speeds up recruitment.And how are they going to come up with 4589 depressed subjects that are treatment failures [<50% response to an SSRI] and get this study done in two years? I haven’t a clue. But the point is clear, this is a race to the finish line, to be the first company to have a Ketamine-like product on the market.
Surprise/Flash: So I just went to ClinicalTrials.gov to look up something about RAP-MD-04 that I was about to write about, and there’s another whole trial! posted on Christmas Day! It’s called Long-term Safety Study of Rapastinel as Adjunctive Therapy in Patients With Major Depressive Disorder [RAP-MD-06]. And this is what I had just typed, "But those things aren’t the most alarming piece of this suite of clinical trials. The fourth trial [RAP-MD-4] is a longer term clinical trial looking at relapse prevention…" I was about to talk about the potential harms. They were talking about an extension study where they were giving an intravenous drug weekly that is a kissing cousin to Ketamine, a hallucinogen. They’ve reported that Rapastunel isn’t a hallucinogen based on one published single shot trial. Now they’re going to give it weekly for up to two years as a preventative, but there’s no contingency for any continued monitoring over the long haul. And Flash, there’s appears a safety analysis. Thought broadcasting? I hope not. Anyway, here’s the new study…

… which looks for all the world like yet another trial using that same cohort. Is that kosher? Basing multiple trials on a single group of subjects? I guess the right thing to do at this point is to back off until Allergan settles down and lands on a scenario that suits them. Is this their first CNS drug trial? They’re sure making one fine mess of things so far…
Sorry, the comment form is closed at this time.