
I recognize when I get on a topic and beat it in the ground, I’m living up to my 1BORINGoldman moniker. And right now, I’m doing that with Vortioxetine [Brintellix® AKA Trintellix®]. But I’ve got my reasons [actually two of them]. But neither reason is to prove to you that this latecomer is a particularly weak addition to an already weak class of drugs – the SSRI/SNRI antidepressants. You already know that.
One reason is in my own history as an eight year amateur Clinical Trial vetter. When I first started looking into these psychopharmacology trials, in spite of having had more than the usual amount of statistical training and experience, the clinical trial motif was new territory – and there was much to learn. But early on, like many of you, I could see that the industry funded trials were regularly distorted. And then there was the absurdity that the data itself was hidden [proprietary property of the sponsor]. And in those few instances where one could nail down the misreporting [because of subpoenaed internal documents or court-ordered data release] by the time those facts were available, they were old drugs either off-patent or nearly so. The profits were already in the bank and the drugs were established and in use. So I resolved to take a look at new drugs that came along, and if the reports looked shaky, perseverate on what was wrong – hoping to join a chorus that might finally move us away from such things in our academic journals. Vortioxetine is both new and shaky, ergo, one of my reasons to stick to it like glue.
But the second reason is that the more I read these clinical trial articles, the more aware I become of how much work goes into putting the commercial spin into every graph, table, sentence, calculation, statistical test, omission, etc. I’ve already mentioned a few in smoke and mirrors…, but there are others everywhere. In one of the the main data tables, I mentioned things like how it was sorted and which units were shown graphically.

[click image for full size]
But then notice the absence of a p-value column, for example. And they show the aggregate results for all studies [Meta-analysis], but then they break out the aggregate for the non-US studies [Meta-analysis (non-US)]. How come? Remember that they make a big deal out of there being a dose response effect and there it is in the non-US data. But why not also break out the US studies? Well because they don’t show a dose response effect – and, for that matter, they don’t show much of any effect at all! a significant omission:
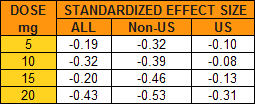
These studies involve thousands of subjects – the kind of numbers required to detect the kinds of small differences they’re reporting. The way they get these big numbers is to use a lot of sites. With the US studies, we know the cities where they were gathered. With the non-US studies, we only know the countries, not the number of sites in each. But even at that, there are many, many sites, in diverse places, each with its own staff and raters. That’s a lot of room for a lot of variability, invisible to the reader [go ahead, click on the image to see what I mean by many, many and diverse].
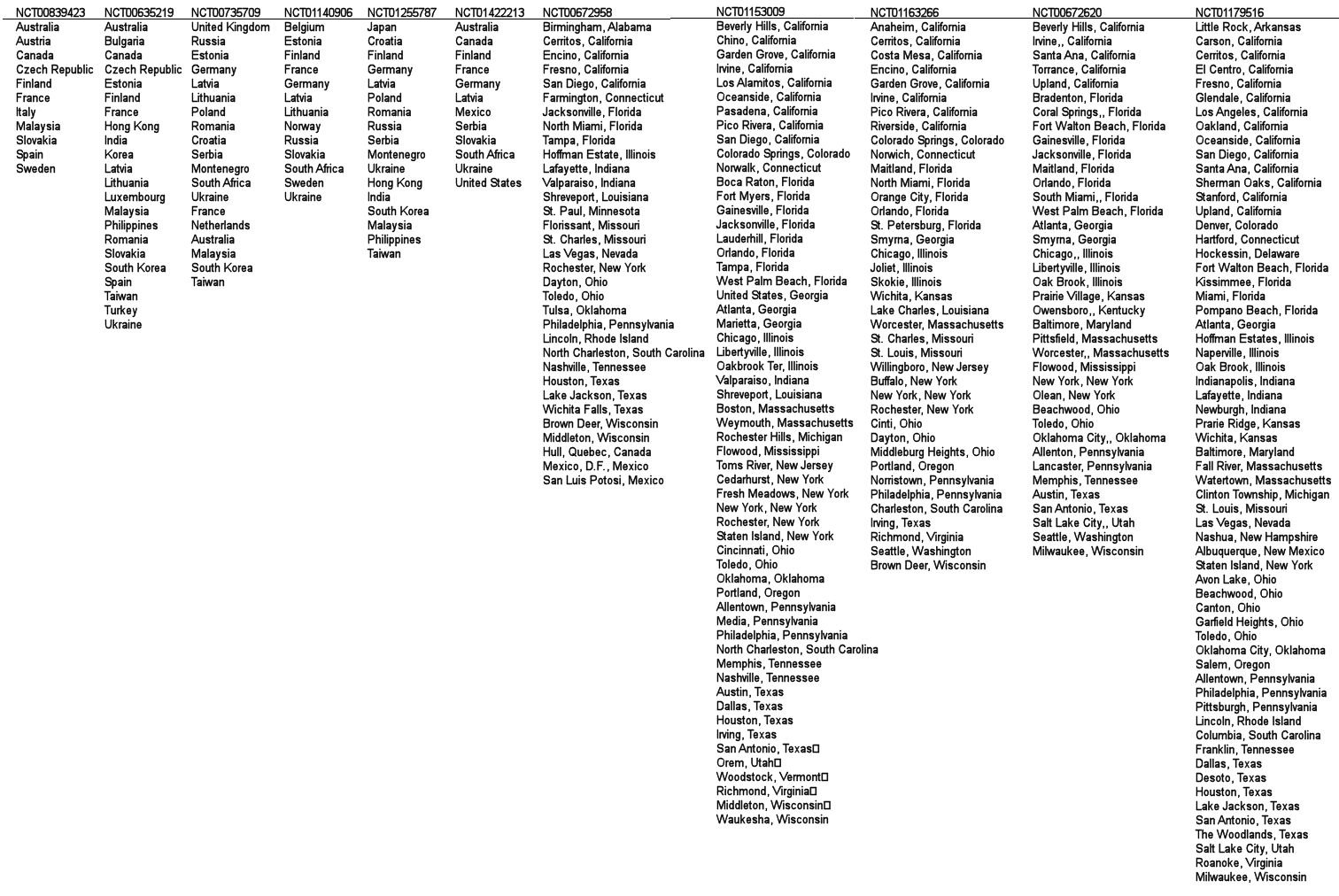
[click image for full size]
I used to just pass over these presentation quirks because I couldn’t prove they were deliberate, what with this being the age of evidence based medicine and all. But they’re so universal, I give them more valence now. But the most damning finding in the industry funded trials and their reports is something that’s hard to quantify, but plain as the nose on your face. It’s the narrative itself, and this is a fine example. It’s a sales pitch, that sings that old song: accentuate the positive, eliminate the negative, latch on to the affirmative, and don’t mess with mister in-between. Just read the discussion. You can’t miss it.
A new term for this kind of thing showed up on Twitter today: “randomized controlled ads.” It makes a nice pair with “experimercial.”
I’m genuinely surprised they didn’t go with “Quintellix” given its theoretical mechanisms of actions.