Well, they finally published the results of the DSM-5 Field Trials. Here are the links to the abstracts and a forest plot of kappa values to look over:
DSM-5 Field Trials in the United States and Canada, Part I: Study Design, Sampling Strategy, Implementation, and Analytic Approaches
by Diana E. Clarke, William E. Narrow, Darrel A. Regier, S. Janet Kuramoto, David J. Kupfer, Emily A. Kuhl, Lisa Greiner, and Helena C. Kraemer
American Journal of Psychiatry. 2012 October 30, AJP in Advance
DSM-5 Field Trials in the United States and Canada, Part II: Test-Retest Reliability of Selected Categorical Diagnoses and Analytic Approaches
by Darrel A. Regier, William E. Narrow, Diana E. Clarke, Helena C. Kraemer, S. Janet Kuramoto, Emily A. Kuhl, and David J. Kupfer
American Journal of Psychiatry. 2012 October 30, AJP in Advance
Objective: The DSM-5 Field Trials were designed to obtain precise [standard error <0.1] estimates of the intraclass kappa as a measure of the degree to which two clinicians could independently agree on the presence or absence of selected DSM-5 diagnoses when the same patient was interviewed on separate occasions, in clinical settings, and evaluated with usual clinical interview methods.
Method: Eleven academic centers in the United States and Canada were selected, and each was assigned several target diagnoses frequently treated in that setting. Consecutive patients visiting a site during the study were screened and stratified on the basis of DSM-IV diagnoses or symptomatic presentations. Patients were randomly assigned to two clinicians for a diagnostic interview; clinicians were blind to any previous diagnosis. All data were entered directly via an Internet-based software system to a secure central server. Detailed research design and statistical methods are presented in an accompanying article.
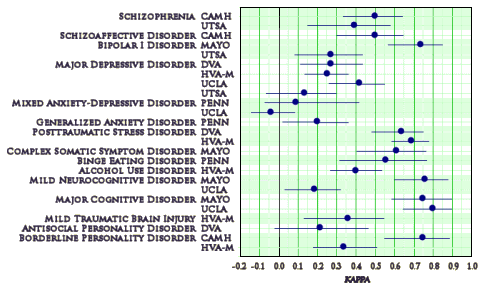
Results: There were a total of 15 adult and eight child/adolescent diagnoses for which adequate sample sizes were obtained to report adequately precise estimates of the intraclass kappa. Overall, five diagnoses were in the very good range [kappa= 0.60–0.79], nine in the good range [kappa= 0.40–0.59], six in the questionable range [kappa= 0.20–0.39], and three in the unacceptable range [kappa values <0.20]. Eight diagnoses had insufficient sample sizes to generate precise kappa estimates at any site.
Conclusions: Most diagnoses adequately tested had good to very good reliability with these representative clinical populations assessed with usual clinical interview methods. Some diagnoses that were revised to encompass a broader spectrum of symptom expression or had a more dimensional approach tested in the good to very good range.
DSM-5 Field Trials in the United States and Canada, Part III: Development and Reliability Testing of a Cross-Cutting Symptom Assessment for DSM-5
by William E. Narrow, Diana E. Clarke, S. Janet Kuramoto, Helena C. Kraemer, David J. Kupfer, Lisa Greiner, and Darrel A. Regier
American Journal of Psychiatry. 2012 October 30, AJP in Advance
I’m going to defer commenting until tomorrow when I can compare them to past results, but on a once over, they look pretty bad…
hat tip to Suzy Chapman 
Off topic of this post, but on re GSK PAXIL 329… take a look at who won the “largest prize” in psychiatry. http://galvestondailynews.com/story/358350 a co-author of PAXIL 329 study…. see how that wheel turned and churned out the drugging of kids, wow and now she is awarded… correct me if I am wrong abt her being the one and the same Karen Wagner…
To a non-psychologist, non-psychiatrist, these look disastrous, even with the reduced standards for good or better.
kappas in the range of 0.40 to 0.59 are considered “good?” What planet to these shills live on?
British Medical Journal moves to flush out secret trial data
LONDON | Wed Oct 31, 2012 6:14am EDT
Oct 31 (Reuters) – The respected British Medical Journal (BMJ) will refuse to publish research papers on drugs unless the clinical trial data behind these studies is made available for independent scrutiny.
http://www.reuters.com/article/2012/10/31/pharmaceuticals-disclosure-bmj-idUSL5E8LV59720121031?rpc=401
It’s pretty clear that the APA and the DSM-5 managers wanted to put lipstick on the pig when reporting these results of the field trials. The very purpose of DSM-III and DSM-IV was to have criteria that could be used reliably across the country, if not around the world. So, the variability between sites as shown in the Table above is a major problem.
To take just one classic condition, Bipolar I Disorder, the Mayo Clinic site came in with a kappa value of ~0.75 whereas the San Antonio site came in with a kappa of around 0.27. You can’t gloss over that discrepancy just by reporting a mean value, which would be around 0.51. This is prima facie evidence of unacceptably poor execution of the field trials.
State-of-the-art psychiatry research!