The Hamilton Rating Scale for Depression[HRSD], also called the Hamilton Depression Rating Scale [HDRS], abbreviated HAM-D, is a multiple item questionnaire used to provide an indication of depression, and as a guide to evaluate recovery. Max Hamilton originally published the scale in 1960 and revised it in 1966, 1967, 1969, and 1980. The questionnaire is designed for adults and is used to rate the severity of their depression by probing mood, feelings of guilt, suicide ideation, insomnia, agitation or retardation, anxiety, weight loss, and somatic symptoms.
I can reminisce about the tricyclic antidepressants too. As a psychiatric resident when I saw hospitalized patients, I saw many whose severe depressions responded to the tricyclics. They were used some in the outpatient clinic at Grady, our charity hospital in Atlanta, but I never personally saw a patient there get much better on them. I usually saw them discontinued because of anticholinergic side effects. There were some older doctors who worked in the clinic as volunteers, and they prescribed a lot of Doxepin. It was a lighter·weight antidepressant that I never saw used in the hospital, but it also had anti·anxiety properties and I presumed that’s why it was being used.
The long and short of it is that I don’t think I wrote a single prescription for an antidepressant in the decade between the time I finished training and the time I left the University – which happened to be around the time that Prozac was introduced. Part of the story was that my University practice was all referrals – personality disorders, eating disorders, students with problems of one sort or another. Since I had never seen antidepressants as much help in that kind of patient, they never came to my mind. I enjoyed my practice and the results, but through the retrospectascope, it even seems strange to me that I didn’t use antidepressants.
Thinking back even further to my days in Internal Medicine, most of what I learned about medications was OJT [on the job training], more on the apprentice model than from books and articles. I’ve always been a reader, but I don’t recall reading a lot about drugs. I recall talking a lot about drugs, or poring through the PDR, therapeutics manuals, and calling people up when I had a case where I needed to get up to speed on some unfamiliar medication. But as the years passed, it was my own experience with a particular medication that mattered the most. I think I grew up with the model that we all did our own "clinical trials." Again, as strange as it sounds today, that was almost a code of honor. Learning to use medications was like learning to discriminate heart murmurs with a stethoscope or palpate the gall bladder in a jaundiced patient. And that model followed me into psychiatry.
But when I first read about people criticizing clinical trials, what they said didn’t compute. The idea of a controlled and protocol driven clinical trial makes total sense – more along the lines of the research in psychology than my former more ethological approach. Vetting a number of clinical trials and finding their deceitful ways on my own made the detractor’s point more palatable. But over time, other things became apparent – obvious things. Here’s a clinical trial where I had the actual raw data available to plot the HAM-D for every subject:
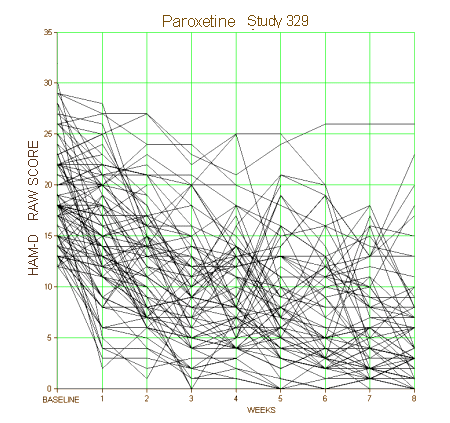
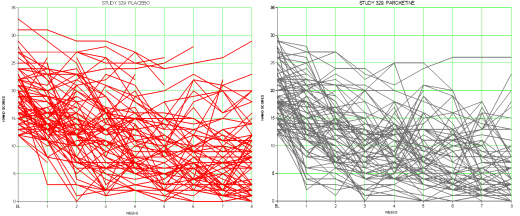
It’s not a great example because it’s Paxil Study 329 which was, in my reading, a negative study presented otherwise, but I think I can still make my point. When I’m in the room with a single patient, which line matters? They only get one. In a world of such small differences, even a non-jury-rigged trial that is statistically significant doesn’t necessarily help. Should I show my patient the plots of these raw results for placebo and drug responses? How about showing them on a Direct-To-Consumer television ad rather than the beautiful smiling people?
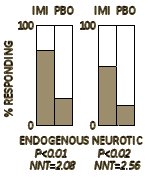 I’d feel a lot better holding up a graph from the 1959 trial by Drs. Ball and Shiloh whose results were a doctor/patient consensus [and would have stood on their own with no statistics involved]. In that case, I’d be sticking close to the clinical question that the patient wants to ask, "What will it do for my depression?" The modern clinical trials in psychiatry are way too sensitive to correlate with palpable clinical improvement. I don’t question that they measure a drug’s antidepressant properties, but in lots of cases, clinical relevance is another matter.
I’d feel a lot better holding up a graph from the 1959 trial by Drs. Ball and Shiloh whose results were a doctor/patient consensus [and would have stood on their own with no statistics involved]. In that case, I’d be sticking close to the clinical question that the patient wants to ask, "What will it do for my depression?" The modern clinical trials in psychiatry are way too sensitive to correlate with palpable clinical improvement. I don’t question that they measure a drug’s antidepressant properties, but in lots of cases, clinical relevance is another matter.
So what to do? What to do? I’d personally like to see the NIMH get over Dr. Insel’s obsession with developing novel new targets and inventing virtual new diagnostic schemes, and focusing on the off-patent old antidepressants we already have that are so widely prescribed. How about some well designed, comparative clinical trials with help-seeking patients in academic centers with both the rating scales and actual hands-on, eyeballs-on, ears-open clinician evaluations [circa 1959]? How about a data-base of subjects to follow with extensive life and family histories, psychometrics galore, and symptom profiles in a setting that approximates clinical practice to replace the dead-end, sterile data from STAR*D? We could even draw some blood for the geneticists of the future. Here’s another novel idea – put the raw data in the public domain for all to see and play around with. There’s enough question in everyone’s mind about these heavily prescribed medications to more than justify the expense. And frankly, the last twenty-five years of research has left us with more questions than answers. Who knows? Maybe we’d see the contested Akathisia after all, or precisely characterize the withdrawal syndromes and relapse rates. Plus, all these academic centers need something to keep them occupied and funded now that the pharmaceutical money is evaporating.
R.E.M.I.N.I.S.C.E.N.C.E.S.: Real Effects of Medication In New Instances of Significant Clinically Evident Neurosis with Clinician Evaluations and Subjective (patient) measures.
Psycritic,
Brilliant! I couldn’t think of one…
Totally. What also should be included is the effect that one drug has on another. It can be profound. Patients and people who prescribe should carefully monitor, and record all changes after starting an additional drug. It should be obvious that chemicals react, but the practice of adding one drug to counter the negative effects of the one before it is routine and apparently unstudied. The brain has to process and deal with those drugs. They don’t just go into the brain and flip a switch, they become a part of the brain’s functioning and efforts to achieve homeostasis.
These cocktails are, in many ways, like throwing a series of chemicals in a pond based on whatever disorder is most apparent to the observer, in an effort to make the pond ecologically healthy or at least not such a mess. It is far more likely to be a study in unintended consequences than it is to make the pond healthy. It can also be compared to the damages done by the unbridled use of pesticides. The brain is a lot more complex than a pond or a patch of dirt and psychiatric drugs can be very blunt instruments.
Psychiatric drugs can be useful, I have no doubt about that; but once a person has been on a series of rotating cocktails, the benefit or damage of a single drug in any cocktail.
And, in addition to the inventories and scales, what if clinicians asked patients what they want to do (something they could do before), make a plan, and see if the patient becomes more or less able to accomplish that plan. Is the problem motivation? A lack of energy? A lack of hope? A lack of mental clarity? A lack of executive control? A lack of confidence? This might be beneficial for assessing which drug might help, with the understanding that the drug is just helping (if it works) and not “fixing” a biological brain glitch.
And always —- informed consent.
…the benefit or damage of a single drug in any cocktail cannot be measured.