Most of us have an incomplete knowledge of Statistical Analysis unless we’ve had formal training and hands-on experience, yet we tend to accept the output from the computer’s statistical packages as if it’s dogma. In academic and commercial laboratories, we count on Statisticians [or trained SAS Programmers] to generate those abstract lettered indices that we discuss as if they’re absolutes – p, d, k, SEM, SD, NNT, OR, etc. And even the experts can’t check things with a pad and pencil. So we’re vulnerable to subtle [and even not so subtle] deceptions. In our RIAT Team’s reanalysis of Study 329, we had decided to follow the a priori protocol, which meant sticking to the protocol defined outcome variables and ignoring those later exploratory variables [in blue in Keller et al‘s Table 2] as discussed earlier.
The Study 329 protocol is clear and precise about statistical testing: parametric Analysis of Variance for the continuous variables and Logistical Regression for the categorical [yes/no] variables. They specified a model containing treatment and investigator with contingencies for interactions between them [since I’ve already put the non-stat-savvy set to sleep, I’m going to dumb this down a bit going forward]. We noticed that our p values differed from those in both the Keller et al paper and the CSR [Full study report acute], even though our open source statistical package [R] is equivalent to their commercial package [SAS] – both available in the Secure Data Portal provided by GSK. While the results for the protocol defined variables were not significant, the numbers still should’ve been close to the same. And there was something else. They were reporting statistics for Paroxetine vs Placebo, Imipramine vs Placebo, and saying that the study was not powered to test Paroxetine vs Imipramine – all pairwise comparisons. Why this was important takes a little explaining.
When a dataset has only two groups [as a study of Paroxetine vs Placebo], pairwise statistical comparisons with something like the familiar t-test are perfectly appropriate. But when you run statistical comparisons on datasets with more than two groups, there’s a two step process. First you test the whole dataset using an OMNIBUS statistical test like Analysis of Variance [ANOVA]. If the whole dataset is significant, then you can run pairwise tests between the various groups to find where the significance lies. But if the OMNIBUS test is not significant, it means that there are no differences among the groups – and that’s the end of that. The pairwise tests are immaterial no matter how they come out. Keller et al had skipped the OMNIBUS tests altogether [never mentioned in the protocol, the paper, or the CSR]. Our results were the OMNIBUS statistics and that’s why they were different. With the protocol-defined variables under consideration, it didn’t matter since nothing was significant no matter what your method. So the question became, "Why bother to skip the OMNIBUS statistical tests?"
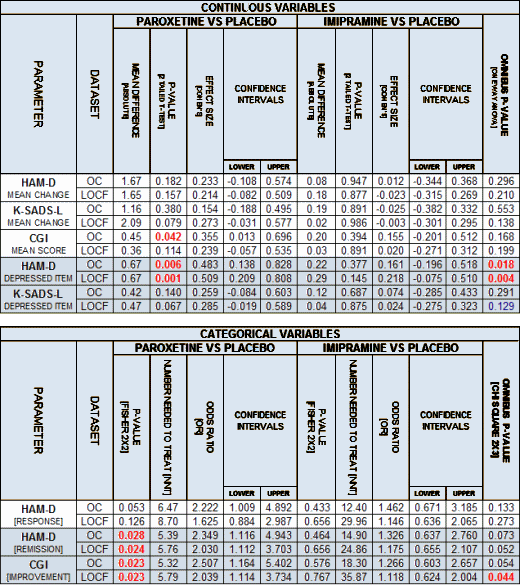
Just one more piece of techno-babble. There’s something more to say about those two minimally significant exploratory variables:
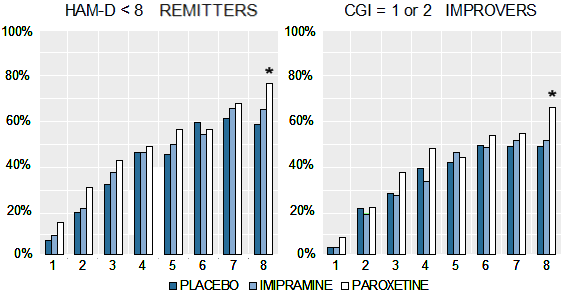
Both of the non-protocol categorical variables were only significant in week 8, suggesting to me that they were probably outliers [flukes]. And, as mentioned earlier, even if you include the rogue non-protocol exploratory variables, applying any correction for multiple variables would wipe out statistical significance for three of the four. That leaves the HAM-D DEPRESSED ITEM as the only statistically significant finding in this entire study – one question on a multi-item rating scale! So in order for Keller et al to reach the conclusion "Paroxetine is generally well tolerated and effective for major depression in adolescents," all three things had a part to play: no correction for multiple variables; redefining a priori to mean before the blind is broken rather than before the study begins; and ignoring the OMNIBUS statistical test.
Mickey, read this earlier:
“The researchers were also able to look at only 93 of the 275 case reports, because they had insufficient time or resources. It is possible that a full re-analysis might change the overall message.” http://www.nhs.uk/news/2015/09September/Pages/Antidepressant-paroxetine-study-under-reported-data-on-harms.aspx
Prior to this, I hadn’t heard that the re-analysis was a partial analysis.
This surprises me – any truth in this?
Hi Mick,
Yes it’s true. The CRFs were overwhelming one page at a time. I don’t think it would’ve made any difference in that we focused on the records identified in Keller et al, drop-outs, etc. Dr. Healy’s first research assistant finally threw up her hands and he actually lost the position. Author Jo took over and put forth a herculean effort. If we could’ve printed them out, we could’ve spread it out among many raters, but we only had a limited number of portals specific to one computer. I had one for efficacy, and the Bangor group had one for harms. It was just not feasible to do them all. Somewhere down the line, we’ll have something to say about that. Being the “first” anything is hard work. In response to your point, the only direction we could go would be to find even more harms. But I feel good about what we were able to get done [Jo probably ought to be knighted]…
Dr Nardo, as I understand your team have been granted access to GSK website by which they gathered the data, however without the right to print or download. My question is – why no one haven’t just taken screenshots or photograph computer screen and then extract text from images with appropriate software (for ex. Abby Finereader,) ? I’m pretty sure it would be illegal however it’s impossible to prove that action if computer wasn’t infected, stored in monitored room or remote accesed by some else.
Thanks Mickey. Oh yes, wonderful effort all round 🙂
Just keeping my nose to the ground to sniff out the inevitable attempts at trying to undermine the findings of the re-analysis.