
by SD TargumJournal of Clinical Psychopharmacology. 2006 26[3]:308-310.
Clinical trials rely on ratings accuracy to document a beneficial drug effect. This study examined rater competency with clinical nervous system rating instruments relative to previous clinical experience and participation in specific rater training programs. One thousand two hundred forty-one raters scored videotaped interviews of the Hamilton Anxiety Scale [HAM-A], Hamilton Depression Scale [HAM-D], and Young Mania Rating Scale [YMRS] during rater training programs conducted at 9 different investigator meetings. Scoring deviations relative to established acceptable scores were used to evaluate individual rater competency. Rater competency was not achieved by clinical experience alone. Previous clinical experience with mood-disordered patients ranged from none at all [18%] to 40 years in 1 rater. However, raters attending their first-ever training session [n = 485] were not differentiated on the basis of clinical experience on the HAM-A [P = 0.054], HAM-D [P = 0.06], or YMRS [P = 0.66]. Alternatively, participation in repeated rater training sessions significantly improved rater competency on the HAM-A [P = 0.002], HAM-D [P < 0.001], and YMRS [P < 0.001]. Furthermore, raters with clinical experience still improved with rater training. Using 5 years of clinical experience as a minimum cutoff [n = 795], raters who had participated in 5 or more training sessions significantly outperformed comparably experienced raters attending their first-ever training session on the HAM-A [P = 0.003], HAM-D [P < 0.001], and YMRS [P < 0.001]. The findings show that rater training improves rater competency at all levels of clinical experience. Furthermore, more stringent criteria for rater eligibility and comprehensive rater training programs can improve ratings competency.
There are sort of two levels for evaluating the outcome of clinical trials of psychopharmacologic treatments. One is statistics. That’s the FDA standard. Their charge is to make sure that a medicine has medicinal properties, isn’t inert like many of the patent medicines of old. And in most cases, that’s that for the FDA – p < 0.05. Clinical significance isn’t their job. A second level might be thought of as the way the Cochrane Collaboration approaches evaluation – not just is it medicinal, but how strong is it. They display and report on the Effect Sizes – things like Cohen’s d, Hedges g, Standardized Mean Difference, Odds Ratio, NNT, NNH. Then they combine these strength of effect measures with the 95% Confidence Intervals [a probability measure] in their familiar forest plots which I find invaluable. But what about what the subjects say? Many of the Observer Rated Metrics have Subject Self-Rated versions that cover the same ground [HAM-D-SR, IDS-SR, QIDS-SR, etc]. And there are others that focus on other areas of subjective experience.
When we sit in our offices, all we have to go on is what our patients have to say about what the medications are doing and how they look when they walk in the door. The scale is simple: "It really helped," "I think it might be helping," "It’s not helping." But the subject as self-rater isn’t so prominently mentioned in the published clinical reports [unless it’s a positive report]. Take for example the recent clinical trials of Brexpiprazole [Rexulti®] in treatment resistant depression that I can’t seem to stop talking about. Remember that there are two sets of efficacy data – a jury-rigged set and the real data [in an appendix]. Here’s some summary info from the real data – primary outcome on top [graphs] and secondary outcomes below [table]:
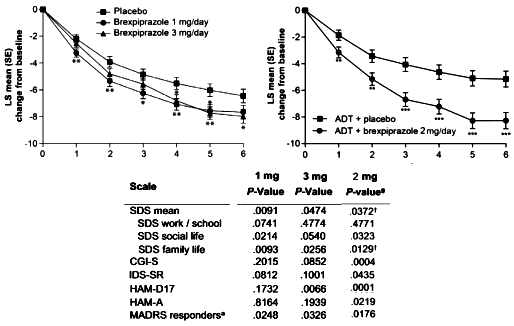
"Brexpiprazole 3 mg showed greater efficacy than placebo (P < .05) on MADRS-defined response rate, CGI-I–defined response rate, and CGI-I at week 6 and in mean change from baseline at week 6 in CGI-S, HDRS-17, HARS, and IDS-SR."
As prescribing physicians, we have access to more information than our patients. All they get is what they see in the media [the actors]. We at least have the papers, but we have to do more these days than just read what’s handed to us. Accepting the deceptive and selective reporting in the published articles just can’t be justified in the climate of our current literature. So it behooves practitioners to go the extra mile to make some simple calculations that regularly go missing, and to take note of metrics like the subject self-ratings that may be mentioned in the Methods, but don’t make it to the Results except buried in a table.
Sorry, the comment form is closed at this time.