by David Beiser, Milkie Vu, and Robert GibbonsPsychiatric Services. Published online: April 15, 2016
Objective: Computerized adaptive testing [CAT] provides improved precision and decreased test burden compared with traditional, fixed-length tests. Concerns have been raised regarding reliability of CAT-based measurements because the items administered vary both between and within individuals over time. The study measured test-retest reliability of the CAT Depression Inventory [CAT-DI] for assessment of depression in a screening setting where most scores fall in the normal range.Methods: A random sample of adults [N=101] at an academic emergency department [ED] was screened twice with the CAT-DI during their visit. Test-retest scores, bias, and reliability were assessed.Results: Fourteen percent of patients scored in the mild range for depression, 4% in the moderate range, and 3% in the severe range. Test-retest scores were without significant bias and had excellent reliability [r=.92].Conclusions: The CAT-DI provided reliable screening results among ED patients. Concerns about whether changes in item presentation during repeat testing would affect test-retest reliability were not supported.
Patients who had a critical illness, were age 17 or younger, were non–English speaking, were without decisional capacity, or had a behavioral health–related chief complaint were excluded. After written consent was obtained, the CAT-DI was administered twice by research assistants using tablet computers. The second test was administered within one to three minutes following the end of the first test.
Depression is associated with increased mortality, adverse health outcomes, and increased overall treatment-related costs. The emergency department [ED] is an important safety net for patients with behavioral health problems and thus may be an ideal setting to diagnose and initiate treatment for patients with depression. Current estimates suggest that between 8% and 32% of ED patients present with depression. However, conducting the detailed assessments of depression severity required to initiate treatment is often infeasible in the ED because of high patient volumes and limited access to behavioral health expertise. Therefore, any strategy that reduces the burden of empirically based assessment of depression has the potential to improve outcomes…
 Let me start over. There’s a whole line of thinking that conceptualizes depression as if it’s an epidemic medical disease. The logic begins with some allusion to the prevalence in the population and the notion that it is rapidly increasing, then progresses to some kind of estimate of the cost in lost productivity and things like over-use of medical services etc. The end point of this logic train is that we need early detection, rapid treatment [antidepressants], and better drugs than the ones we currently have.
Let me start over. There’s a whole line of thinking that conceptualizes depression as if it’s an epidemic medical disease. The logic begins with some allusion to the prevalence in the population and the notion that it is rapidly increasing, then progresses to some kind of estimate of the cost in lost productivity and things like over-use of medical services etc. The end point of this logic train is that we need early detection, rapid treatment [antidepressants], and better drugs than the ones we currently have.I hope this article comes to us as an anachronism past it’s prime. It started in 2002 when Dr. Gibbons, a statistician at the University of Chicago, got an NIMH Grant to develop computerized screening instruments [what!…]. That same year, Dr. David Kupfer et al published A Research Agenda for the DSM-V, laying out a plan for a biologically-based medical psychiatry, the dream of many since the 1980 DSM-III. And 2002 was also the year Tom Insel was appointed head of the NIMH [Psychiatry as a Clinical Neuroscience Discipline]. Robert Gibbons part in this story has been a dogged determination to undermine the Black Box warning on the antidepressants and an equally persistent campaign to advance this screening instrument. The CAT-DI tools were developed with NIMH funds and then turned into a for-profit enterprise in concert with David Kupfer, his wife Elizabeth Frank, and others on the sly [When is Disclosure Not Disclosure?]. So there’s an attempt to capitalize on this screening instrument.
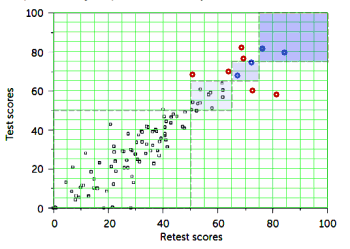
If this article is about evaluating the test-retest reliability of his CAT-DI instrument, and using the ER patients was a way to get a spread out cohort for that test, it didn’t come out so well. Only 2/5 in the severe range and 2/5 in the moderate range were reliable – that’s 4/10 in the ranges that mattered:
But beyond being a weak test [… Not Ready for Prime Time], the gross improprieties in its development, and the obvious profit motives involved, I wonder about the whole idea of screening people for depression. The questions asked on any such instrument that would register significant depression aren’t subtle. If a person is answering them honestly enough to generate a high score, they’re not trying to hide being depressed, so it’s going to show to anyone who is engaged and looking.
It may be that the authors are foolish when they write things like “… thus may be an ideal setting to diagnose and initiate treatment …,:” But the purpose of the paper is stated clearly in the abstract. It is to measure test-retest reliability. It may be foolish to use such tests for diagnosis, but it is good to understand the reliability of the test.
I have been lurking and reading this blog since its beginning, and I have a comment. I am a rheumatologist (around Mickey’s age) who used pain, functional and psychological questionnaires at every patient visit over a 30 year period. I never used such data for diagnosis, but I did use them to help understand patients’ problems. To that end, I think questionnaires are useful. It is the widespread, unthinking and stupid use of questionnaires that is harmful. I used the data also to publish and understand outcomes in rheumatic diseases (See F Wolfe – National Data Bank for Rheumatic Diseases in Google search or Pub Med).
If I might offer one criticism to this group, it is that you are seeing all of this largely through expert psychiatric eyes. Questionnaires data, wisely used, could help those of us who are non-psychiatrist, though not in the unthinking way it is now being done.
Interesting comment Fred Wolfe.
I have found non psychiatric questionnaires I was asked to fill out at doctors’ offices totally useless as they didn’t address my concerns.
In one situation, I felt like I was provided alot of push back even though I was respectful about my decision. As a compromise, I finally agreed to fill out one section that was deemed high priority.
Obviously, you totally read what your patients marked in an attempt to understand their problems. But I have found that most of the time, doctors don’t read what patients say. And since it takes me alot of effort get through one, obviously if I feel it is pointless to fill it out based on my previous experiences, I am just not going to do it.
When seen in a clinic/office setting a patient with depression comes away with more than a diagnosis and a prescription. They comes away with the sense the someone who has gotten to know them (full interview), knows about their depression (psychosocially informed), is competent to help keep them safe (trained in the work – not ED doc). Further they sought out the treatment (autonomy respected); it wasn’t pushed on them after a presentation to the local ED with something unrelated. Finally that person will see the patient again and remember them. All of this is built into the structure in which psychiatrists historically saw patients. Separate from the observations/content of what the psychiatrist says to the patient, this structure maximizes the odds that the patient improves. There aren’t short cuts. We as psychiatrists need to make the argument that this has value. It would be nice to see a study comparing the efficacy of fluoxetine given in an office by a psychiatrist to prozac given out in the ED.
Finally why are so many patients presenting in the ED (or anywhere) experiencing such a high level of apparent untreated depression? Because the mental health infrastructure has been dismantled. Why are our thought leaders never pointing this out but instead kowtowing to the powers that be? If a person was cynical they might get the sense that the leadership was chosen specifically for their skill at this kowtowing behavior. If a person was paranoid they might fear that psychiatrist as app will be following psychiatrist as backroom collaborator.
Elaine,
Thanks…
Unfortunately there is no reason to think these screening tests are going to be wisely used in the age of horrible EHRs and fifteen minute medication checks. Thinking won’t be going on because there isn’t time to think. I’m focused on what will happen under the constraints of modern medicine, not an ideal setting.
If you’re going to screen for mental illness, it can’t correctly be done in fifteen minutes by someone who doesn’t have mental health training.
Wait til this becomes standard in schools, when various adolescent acting out episodes will be mislabeled as depression.
Just curious, are you the Dr. Wolfe who coined fibromyalgia and later became a skeptic?
I didn’t put it together at first.
“Later became a skeptic,” I guess that’s right.
If there is room in medical care for a measurement of weight or blood pressure or some blood value, than there also should be a way to measure patients’ feelings and concerns, and functional ability. Short, simple questionnaires can help doctors and patients understand each other if the results are available before the patient interview and not just part of mandated collections.
I agree that “there is no reason to think these screening tests are going to be wisely used in the age of horrible EHRs and fifteen minute medication checks.”
Whatever one thinks about the legitimacy of fibromyalgia including what it is or the degree to which it is socially constructed, the current fibromyalgia criteria mention depression and ask that physicians and patients think about somatic symptoms.
FWIW, disease mongering and expansion of disease in the arena of fibromyalgia parallels that of the psychiatric literature. Almost all of those who work in the area haver had support from pharma. In work that we now have under review, using the National Health Interview Survey, we found that 75% of persons in the general population who receive a fibromyalgia diagnosis would not satisfy criteria for fibromyalgia. It is an illness in which pharma has succeeded in expanding close to their wildest dreams.
Thanks for the comments. In my first career, I was a Rheumatologist and retain some of the principles I learned there to the present. It was there I came to appreciated the use of criteria to diagnoses diseases of unknown etiology, and it was later in psychiatry where I learned the other side of that coin. It was in Rheumatology I learned to see all medications as therapeutic trials rather than tagging medications for specific conditions. And my history with Fibromyalgia sounds like it is similar to yours. The concept was helpful early on with certain patients who were suffering a lot with something that needed a name and some general principles that actually helped. I recall others like chronic fatigue syndrome that had a similar trajectory. In psychiatry where the objective markers never came, we have a book full of such diagnoses.
Your comments about the screening help in that they make me focus on why I find this screening for depression so odious [and I really do]. So my conclusions don’t change, but your point is well taken, and I guess there’s a blog about all the other factors that are as hard to quantify as depression itself, but I’ll think about it and give it a shot…