 |
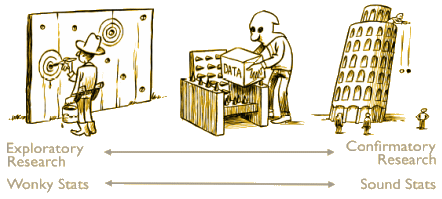
| Figure A1. A continuum of experimental exploration and the corresponding continuum of statistical wonkiness. On the far left of the continuum, researchers find their hypothesis in the data by post hoc theorizing, and the corresponding statistics are “wonky”, dramatically overestimating the evidence for the hypothesis. On the far right of the continuum, researchers preregister their studies such that data collection and data analyses leave no room whatsoever for exploration; the corresponding statistics are “sound” in the sense that they are used for their intended purpose. Much empirical research operates somewhere in between these two extremes, although for any specific study the exact location may be impossible to determine. In the grey area of exploration, data are tortured to some extent, and the corresponding statistics are somewhat wonky. |
Sometimes, a good cartoon can say things better than volumes of written word. This one comes from the exaplanatory text accompanying a republication and translation of Adrian de Groot‘s classic paper on randomized trials explaining why they must be preregistered [see The Meaning of “Significance” for Different Types of Research, the hope diamond…, Why we need pre-registration, For Preregistration in Fundamental Research]. It’s the central point in the proposal suggested by Dr. Bernard Carroll’s Healthcare Renewal blog [CORRUPTION OF CLINICAL TRIALS REPORTS: A PROPOSAL].
The COMPare Trials Project.Ben Goldacre, Henry Drysdale, Anna Powell-Smith, Aaron Dale, Ioan Milosevic, Eirion Slade, Philip Hartley, Cicely Marston, Kamal Mahtani, Carl Heneghan.www.COMPare-trials.org, 2016.
"Our gold standard for finding pre-specified outcomes is a trial protocol that pre-dates trial commencement, as this is where CONSORT states outcomes should be pre-specified. However this is often not available, in which case, as a second best, we get the pre-specified outcomes from the trial registry entry that pre-dates the trial commencement. Where the registry entry has been modified since the trial began, we access the archived versions, and take the pre-specified outcomes from the last registry entry before the trial began." He explains this further in the FAQ on their website…
He has some hard working medical students and volunteer faculty working on his team and they checked all the trials in five top journals over a four month period last winter, comparing protocol defined outcomes against published outcomes. Here’s what they found:
| TRIALS CHECKED |
TRIALS WERE PERFECT |
OUTCOMES NOT REPORTED |
NEW OUTCOMES SILENTLY ADDED |
| 67 | 9 | 354 | 357 |
And when they wrote the editors about the discrepancies, only 30% were published. And when authors do respond, they are sometimes combative or defensive [sometimes the COMPare guys get it wrong and apologize, but that’s not often]. I won’t go on and on. The web site is simple and has all the info clearly presented. Epidemic Outcome Switching! Check and Mate!
I have a minor quibble with your “wonky science” brief. You cite Adrian De Groot’s May, 2014 paper as a “classic” on randomized trials. While I agree that it is an excellent statement, there are much earlier sources for guidance that have been used for years in teaching research and statistics.
For example, I still have on my book shelf a dog-eared copy of William L. Hays, Statistics for Psychologists. New York: Holt, Rinehart and Winston, 1963 that I used in graduate school and continued to use in teaching research and statistics to graduate school students for many years. It contains detailed content about hypothesis testing and the underlying assumptions of hypothesis testing.
All statistical tests of differences between various kinds of treatment must conform exactly to the rules of statistical inference on the basis of a random sample from known universe. The known universe, whether human or one of a non-human animal species, is defined for its applicability in testing the truth of the theory from which the hypotheses are derived. It is an exercise in deductive reasoning . . . first, the theory; second, the derivative hypotheses; third, the design of the experiment to test the hypotheses. The design of the experiment includes definition of an appropriate sampling universe.
All of this hypothetico-deductive thinking necessarily takes place before members of the defined sampling universe are selected. The opposite to hypothetico-deductive thinking is inductive reasoning based on observation or measurement of uncontrolled events happening in nature.
The design of an experiment and its implementation presents threats to internal and external validity. In another early classic, Experimental and Quasi-Experimental Designs for Research. Boston, Houghton Mifflin, 1963. D.T Campbell and J.C. Stanley list nine threats to internal validity that exist which act as rival explanations for changes or differences that are thought to be the effects of intervention or treatment. See: http://jwilson.coe.uga.edu/EMAT7050/articles/CampbellStanley.pdf
I conclude on the basis of these 53 year old sources of guidance on how to conduct and analyze experiments that It is not so much that the research community has not been taught or does not know and understand the rules as much as too many of its members are dishonest. Their conduct is the behavior of knaves, not fools.
So, now you have some old texts that have been used for generations in teaching research and statistics to explain the “why” and wherefores of the a priori Protocol and SAP for conducting and reporting the outcomes of randomized controlled trials (RCTs).
Accent here is on “controlled” experiment or trial via the randomized selection of members of the known universe. It is randomization that theoretically eliminates sources of bias. In the real world this does not always happen. The design of the experiment often requires additional measures to detect biases that may still lurk despite randomization.
BTW, it’s easier to conduct an RCT on rats than on humans. When, despite all precautions, one or more of the lady black-hooded rats in my graduate school learning experiments got pregnant, I simply euthanized the entire sample and started over afresh with a new one.
This the long version of the importance of Dr. Bernard Carroll’s “Corruption of Clinical Trial Reports: A Proposal.” It brings us back to the basics and signals the level of corruption that threatens the very possibility of an “evidence based medicine.”