Okay, I promise not to do this over and over – micro-dissect articles. But indulge me this one time. The way I ran across this article on Lexapro in adolescents is pertinent. I was looking at the Columbia Suicide Scale because I’m thinking the pharmaceutical people are revving up for another assault on the "black box warning" about SSRIs in kids, and they’re gravitating towards the Columbia–Suicide Severity Rating Scale [C-SSRS]. This article was one of the first places it was tested. That’s how I got here, but when I read the article, my direction changed. I wanted to deconstruct it because I think it needs deconstructing. So what follows is a brief description of why I think such a thing…
Escitalopram in the treatment of adolescent depression:
a randomized placebo-controlled multisite trial.
by Emslie GJ, Ventura D, Korotzer A, and Tourkodimitris S.
Journal of the American Academy of Child and Adolescent Psychiatry.
2009 48[7]:721-729.
NCT00107120
SOURCE: University of Texas Southwestern Medical Center at Dallas, Dallas
OBJECTIVE: This article presents the results from a prospective, randomized, double-blind, placebo-controlled trial of escitalopram in adolescent patients with major depressive disorder.
METHOD: Male and female adolescents [aged 12-17 years] with DSM-IV-defined major depressive disorder were randomly assigned to 8 weeks of double-blind treatment with escitalopram 10 to 20 mg/day [n = 155] or placebo [n = 157]. The primary efficacy parameter was change from baseline to week 8 in Children’s Depression Rating Scale-Revised [CDRS-R] score using the last observation carried forward approach.
RESULTS: A total of 83% patients [259/312] completed 8 weeks of double-blind treatment. Mean CDRS-R score at baseline was 57.6 for escitalopram and 56.0 for placebo. Significant improvement was seen in the escitalopram group relative to the placebo group at endpoint in CDRS-R score [-22.1 versus -18.8, p =.022; last observation carried forward]. Adverse events occurring in at least 10% of escitalopram patients were headache, menstrual cramps, insomnia, and nausea; only influenza-like symptoms occurred in at least 5% of escitalopram patients and at least twice the incidence of placebo [7.1% versus 3.2%]. Discontinuation rates due to adverse events were 2.6% for escitalopram and 0.6% for placebo. Serious adverse events were reported by 2.6% and 1.3% of escitalopram and placebo patients, respectively, and incidence of suicidality was similar for both groups.
CONCLUSIONS: In this study, escitalopram was effective and well tolerated in the treatment of depressed adolescents.
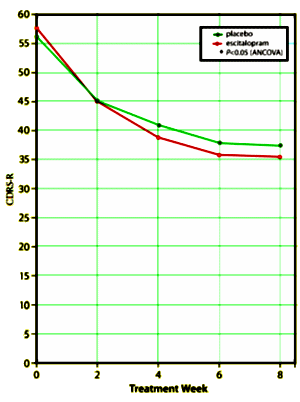 This is a Forest Research Institute Study directed by Daniel Ventura PhD conducted at 28 US sites between March 2005 and May 2007 on children ages 12 – 17 with MDD comparing Placebo and Escitalopram for 8 weeks. The study was funded by Forest Laboratories and three of the authors, Daniel Ventura PhD, Andrew Korotzer PhD, and Stavros Tourkodimitris PhD, are employees of the Forest Research Institute. Graham. Emslie MD is not mentioned on the Clinical Trial site except in a reference as first author on this article. The Children’s Depression Rating Scale-Revised [CDRS-R] score using the last observation carried forward approach [reformatted by me to show the mean raw scores full scale] is shown on the right [green = Placebo and red = Escitalopram]. The differences are statistically significant for the 0, 4, 6, and 8 week visits. There were 158 subjects in each arm with drop-out rates of 16% [Placebo] and 20% [Escitalopram] over the 8 weeks.
This is a Forest Research Institute Study directed by Daniel Ventura PhD conducted at 28 US sites between March 2005 and May 2007 on children ages 12 – 17 with MDD comparing Placebo and Escitalopram for 8 weeks. The study was funded by Forest Laboratories and three of the authors, Daniel Ventura PhD, Andrew Korotzer PhD, and Stavros Tourkodimitris PhD, are employees of the Forest Research Institute. Graham. Emslie MD is not mentioned on the Clinical Trial site except in a reference as first author on this article. The Children’s Depression Rating Scale-Revised [CDRS-R] score using the last observation carried forward approach [reformatted by me to show the mean raw scores full scale] is shown on the right [green = Placebo and red = Escitalopram]. The differences are statistically significant for the 0, 4, 6, and 8 week visits. There were 158 subjects in each arm with drop-out rates of 16% [Placebo] and 20% [Escitalopram] over the 8 weeks.
Under Efficacy, they reported [read this carefully]:
There were significant differences between treatment groups in baseline CDRS-R and CGI-S scores, indicating greater depression severity in the escitalopram group; nevertheless, these differences were not clinically significant. In contrast, there was no difference in baseline CGAS scores (Table 2).
Primary Outcome: Escitalopram treatment produced significantly greater improvement in mean CDRS-R scores than placebo treatment at endpoint when analyzed using the LOCF approach (least squares mean difference [LSMD], j3.356; p = .022; Table 2), with an effect size of 0.27. Significant differences in CDRS-R scores favoring escitalopram over placebo were observed beginning at week 4 (LSMD, j3.371; p = .006; ANCOVA; Fig. 2). Sensitivity testing using the mixed model for repeated measures approach yielded similar findings at endpoint (LSMD, j3.129; p = .035). In the observed cases analysis, there was no difference in CDRS-R improvement between the escitalopram group (j24.6 T1.24) and the placebo group at week 8 (j21.9 T 1.29; LSMD,j2.787; p = .071; ANCOVA).
Primary Outcome: Escitalopram treatment produced significantly greater improvement in mean CDRS-R scores than placebo treatment at endpoint when analyzed using the LOCF approach (least squares mean difference [LSMD], j3.356; p = .022; Table 2), with an effect size of 0.27. Significant differences in CDRS-R scores favoring escitalopram over placebo were observed beginning at week 4 (LSMD, j3.371; p = .006; ANCOVA; Fig. 2). Sensitivity testing using the mixed model for repeated measures approach yielded similar findings at endpoint (LSMD, j3.129; p = .035). In the observed cases analysis, there was no difference in CDRS-R improvement between the escitalopram group (j24.6 T1.24) and the placebo group at week 8 (j21.9 T 1.29; LSMD,j2.787; p = .071; ANCOVA).
There were significant differences between treatment groups in baseline CDRS-R and CGI-S scores, indicating greater depression severity in the escitalopram group; nevertheless, these differences were not clinically significant.

The baseline differences are shown in this partial reproduction of their Table. What they’re talking about is the 1.6 point difference in the Placebo/Escitalopram CDRS-S scores [57.6 – 56.0 = 1.6]. You can see that difference in starting place on my graph above. It doesn’t show on their version because they used differences from baseline rather than raw scores. Here’s the published graph using differences:
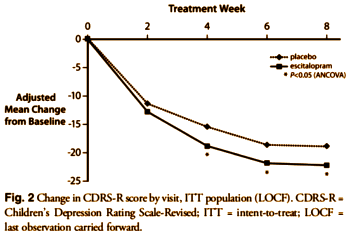
The justification for this statement "nevertheless, these differences were not clinically significant" is nowhere to be found. Note also that this display method amplifies the differences.
In the observed cases analysis, there was no difference in CDRS-R improvement between the escitalopram group (j24.6 T1.24) and the placebo group at week 8 (j21.9 T 1.29; LSMD,j2.787; p = .071; ANCOVA).
What’s this about? "no difference"? My graph, their table, and their published graph are all data adjusted by the LOCF method. If you don’t know what LOCF and MMRM mean, I had a shot at explaining them at this time last year [contents of an empty mind…]. What this means is if they eliminate the fancy corrections for dropped-subjects/missing-values and just analyze the cases they actually have data for, the study was a bust – insignificant! So the validity of their conclusions hinges on the validity of their correction methods. Now for a personal disclosure. If you read this blog often, you’ve noticed that I often redraw graphs from studies aiming towards getting as close to the raw data as possible. My bias is that if you can’t see it in the raw data, it’s probably not there. A corollary would be, if you have to use correction techniques to achieve significance, I say BLEEP! So in this study they show LOCF, they say MMRM [a less error prone method], but only mention observed cases analysis in passing. BLEEP!
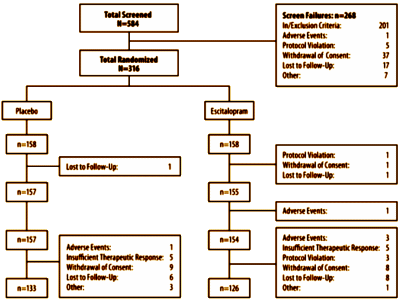
The abstract concludes. "In this study, escitalopram was effective and well tolerated in the treatment of depressed adolescents." In the full text, they explain their wimpy results, "For clinicians, a limitation of this trial is in determining the clinical significance of the results. Whereas the overall effect of medication is robust, the drug-placebo difference is modest." Which brings me to my final point. How can they say that "the overall effect of medication is robust?" As best I can tell, no author saw any of these subjects, ever. They were spread around in 28 other sites. No author was even a site coordinator, and according to the history on the Clinical Trial site, UT Southwestern [home of the first author] was a late comer to the study. As a matter of fact, that’s almost universal – the authors of these Clinical Trials papers, whether the ones listed or their poltergeist alter-egos, have not seen the subjects. They’ve only seen data. So:
-
The data is deceptively displayed. Using the change from baseline instead of the raw scores hides the difference between groups and the small magnitude of difference, as does not showing the full scale.
-
The display of only the corrected data for statistical calculations hides the insignificance of the raw data.
-
Using LOCF as a primary method relies on the assumption that drop-outs are uniform between groups which is not true in their displayed flow data.
-
Calling the clinical response "robust" is indefensible, as is saying the difference between baseline scores "clinically insignificant." That difference isn’t that far from their drug effect difference on which they base their conclusions.
I’d say that it’s a clinically insignificant study, plain and simple – flotsom in the sea of debris that unnecessarily clogs our literature. Thanks for letting me vent…
[The Columbia–Suicide Severity Rating Scale [C-SSRS]? Another day…]
Sorry, the comment form is closed at this time.