Development of a Computerized Adaptive Test for Depression
by Robert D. Gibbons, PhD; David J. Weiss, PhD; Paul A. Pilkonis, PhD; Ellen Frank, PhD; Tara Moore, MA, MPH; Jong Bae Kim, PhD; David J. Kupfer, MD
Archives of General Psychiatry. 2012 69[11]:1104-1112.
Context: Unlike other areas of medicine, psychiatry is almost entirely dependent on patient report to assess the presence and severity of disease; therefore, it is particularly crucial that we find both more accurate and efficient means of obtaining that report.Objective: To develop a computerized adaptive test (CAT) for depression, called the Computerized Adaptive Test–Depression Inventory (CAT-DI), that decreases patient and clinician burden and increases measurement precision.Participants: A total of 1614 individuals with and without minor and major depression were recruited for study. Main Outcome Measures: The focus of this study was the development of the CAT-DI. The 24-item Hamilton Rating Scale for Depression, Patient Health Questionnaire 9, and the Center for Epidemiologic Studies Depression Scale were used to study the convergent validity of the new measure, and the Structured Clinical Interview for DSM-IV was used to obtain diagnostic classifications of minor and major depressive disorder.Results: A mean of 12 items per study participant was required to achieve a 0.3 SE in the depression severity estimate and maintain a correlation of r=0.95 with the total 389-item test score. Using empirically derived thresholds based on a mixture of normal distributions, we found a sensitivity of 0.92 and a specificity of 0.88 for the classification of major depressive disorder in a sample consisting of depressed patients and healthy controls. Correlations on the order of r=0.8 were found with the other clinician and self-rating scale scores. The CAT-DI provided excellent discrimination throughout the entire depressive severity continuum (minor and major depression), whereas the traditional scales did so primarily at the extremes (eg, major depression).Conclusions: Traditional measurement fixes the number of items administered and allows measurement uncertainty to vary. In contrast, a CAT fixes measurement uncertainty and allows the number of items to vary. The result is a significant reduction in the number of items needed to measure depression and increased precision of measurement.
Results of this study reveal that we can extract most of the information (r = 0.95) from a bank of 389 depression items using a mean of only 12 items (median of 2 minutes 17 seconds) per study participant. The paradigm shift is that rather than using a fixed number of items and allowing measurement uncertainty to vary, we fix measurement uncertainty to an acceptable level for a given application and allow the number and specific items administered to vary from participant to participant. As an example, changing our termination threshold from an SE of 0.30 to 0.40 decreased the mean number of items administered from 12 to 6, with only a small corresponding decrease in correlation with the total 389-item score (r = 0.95 to r = 0.92). Such efficiency would permit depression screening of large populations necessary for conducting studies of psychiatric epidemiology and determining phenotypes for large-scale molecular genetic studies.
They give some samples of successive questions [shown stripped of the indices that make the algorithm work]:
| Patient 1 (low severity) | ||
| I felt depressed. | A little of the time | |
| Have you been in low or very low spirits? | A little of the time | |
| How much were you distressed by feelings of worthlessness? | A little bit | |
| I had difficulty sleeping. | A little bit | |
| How much have you felt discouraged? | A little bit | |
| Did fatigue interfere with your mood? | Occasionally | |
| How often has feeling depressed interfered with what you do? | No more than usual | |
| How much were you distressed by feeling everything was an effort? | A little bit | |
| Have you had problems accomplishing less than you would like with your work or other regular daily activities as a result of emotional problems (such as feeling depressed or anxious)? | No | |
| How much of the time have you been moody or brooded about things? | A little of the time | |
| Did you feel isolated from others? | A little of the time | |
| Patient 2 (high severity) | ||
| I felt depressed. | Most of the time | |
| Have you felt that life was not worth living? | Quite a bit | |
| Have you been in low or very low spirits? | Most of the time | |
| I felt gloomy. | Quite a bit | |
| How much have you felt that nothing was enjoyable? | Quite a bit | |
| How much were you distressed by blaming yourself for things? | Quite a bit | |
| How much were you distressed by feeling everything was an effort? | Quite a bit | |
The frequency of the scores is shown left below with mathematically fit normal distribution curves based on the bayesian information criterion conclusion that the best fit favors two populations. The right one is my version, stripped of the fitted curves:
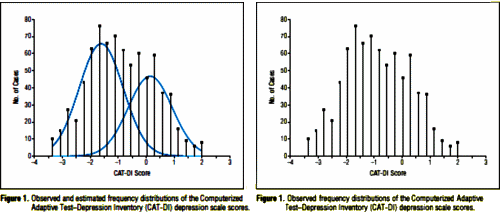
I am underwhelmed that the psychometric indices of depression have added much to the care of depressed patients in this recent era of clinical trials. The introduction of population statistics allows small but statistically significant differences to substitute for true clinical gains ["robust response"], but I have no personal ideas for how to improve things. In the case in point, there’s little doubt that the results correlate with those of other questionnaires and that the test is faster. The relevance, however, is in question.
I can generate all kind if criticisms. The discriminatory power of the questions as I read them isn’t apparent or intuitive. Why is the left curve larger in it if the sample population is skewed the other way? Which of the various groups mentioned in the text was used for that figure? How would this test perform with serial use as in a clinical trial since the test itself changes along the way? blah, blah blah. But my real complaint is the same as it was for Gibbons et al’s previous articles. In spite of the overinclusion of jargon and a tour de force of statistical procedures, there’s no data. And of the three advertised online supplements, only one is actually present – a medley of greek letters and integral symbols about some of the statistical manipulations. I can’t check anything, or address any of my concerns. You can’t either. I can’t imagine a peer reviewer would be in any better position. In these days, and with Gibbons track record, that won’t do.
Such efficiency would permit depression screening of large populations necessary for conducting studies of psychiatric epidemiology and determining phenotypes for large-scale molecular genetic studies.
Funding/Support: This work was supported by grant R01- MH66302 from the National Institute of Mental Health…
Additional Information: The CAT-DI will ultimately be made available for routine administration, and its development as a commercial product is under consideration…
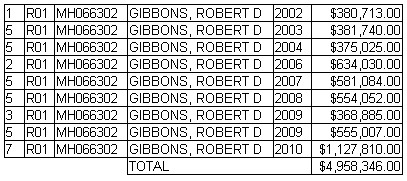
[from the NIH RePORTER]
This looks like a brilliant Artificial Intelligence answer to the wrong question. Like, don’t we already have short screening tests for depression? Don’t they do just as well as this cumbersome monstrosity? Why do we need this redundant project? Why the note of triumphalism about simply distinguishing between normal subjects and depressed patients? And why is NIMH throwing money at it? Looks like foolish techno-dazzle to me.
5 MILLION DOLLARS FOR THIS NONSENSE? If you want to go this route, just give them a BDI-II. JEEZ!!!!!
Wouldn’t those screening tools work a bit better if they asked what happened to someone instead of what’s wrong with them?