The article in the last post [gone missing…] compared the studies of the antidepressants submitted to the FDA with the ones that actually got published. But they looked at something else too, something beyond gone missing. They looked at the strength of the drug effect in the FDA version compared to the published versions. That moves us into the area of dodgy studies [studies that have been dolled up]. If I may quote myself [an anatomy of a deceit 3…]:
Almost everyone knows what a p value is – how probable is it that a difference is real and not just a sampling error? And we know p < 0.05 is good enough; p < 0.01 is real good; and p < 0.001 is great… But all the p value tells us is that there’s a difference. It says nothing about the strength of that difference. A cup of coffee helps some headaches; three Aspirin tablets is a stronger remedy; and a narcotic shot is usually definitive. All are significant, but there’s a big difference in the strength of the effect. There are three common ways to express the strength of the effect mathematically: the Effect Size, the Number Needed to Treat; and the Odds Ratio. Here’s just a word about each of them:
Obviously, effect size is what a clinician really wants to know about a medication – is it likely to have a robust, clinically significant effect on the patient’s symptoms? But talking about effect size is easier than understanding it [1][2][3]. There’s Cohen’s d and Hedges’ g and plenty else to make effect size the stuff of graduate school instead of blogs. For our purposes, 0.2 is a small effect, 0.5 is medium, and 0.8 is large. But all is debatable and without the primary raw data, it has to be calculated indirectly. So it’s mainly used in meta-analyses where it’s power lies – comparisons. And that’s what they did in the study reported in gone missing…. On the left, they compared the effect size between the unpublished and published studies. As you might expect, big differences, again showing the effect [and motive] of publication bias. But look on the right. Here’s what you’re seeing in their words:
The effect-size values derived from the journal reports were often greater than those derived from the FDA reviews. The difference between these two sets of values was significant whether the studies (P=0.003) or the drugs (P=0.012) were used as the units of analysis [see Table D in the Supplementary Appendix].
The effect sizes:
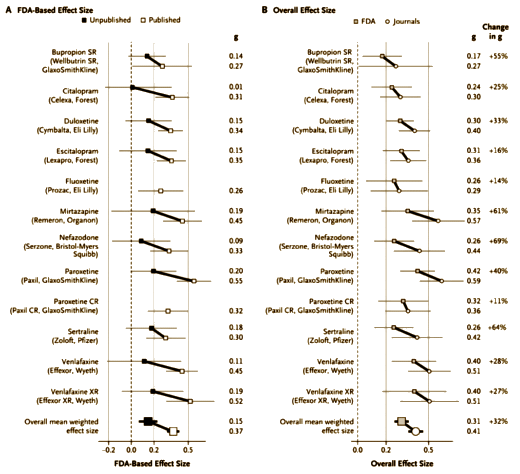
So, to change metaphors for a moment, on the left sins of omission, on the right, sins of commission. I called the latter "another kind of publication bias [effect size inflation]" in the last post, but that’s not quite right. It’s just another example of why we need to insist on the raw data in All Trials – another mechanism for creating dodgy studies [as if there weren’t enough already].
I mentioned that this same group did a similar study in 2012 on the Atypical Antipsychotics [at least that much…]. There weren’t so many studies obviously gone missing and the sins of commission weren’t so blatant. I’d love to say that since these are later studies, maybe things are improving integrity-wise. But I expect that it simply means that the Atypicals are more potent drugs than the Antidepressants. Their problem is in the area of toxicity rather than ineffectiveness. The dodginess jumped from efficacy to safety/side effects.
Here are the comparable plots:
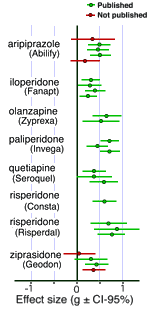
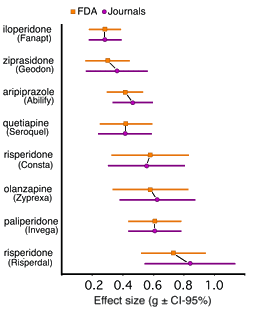
I added these because the difference in effects sizes strikes me as right from my limited clinical experience using the Atypicals drugs in Schizophrenia. And it points out something – the drugs introduced later are less potent. New doesn’t mean better in the world of me-too…
Brilliant charting, thanks, Dr. Mickey!