Early evidence on the effects of regulators’ suicidality warnings on SSRI prescriptions and suicide in children and adolescents. [see peaks and valleys…, watchful waiting…]
by Gibbons RD, Brown CH, Hur K, Marcus SM, Bhaumik DK, Erkens JA, Herings RM, Mann JJ.
American Journal of Psychiatry. 2007 Sep;164[9]:1356-63.
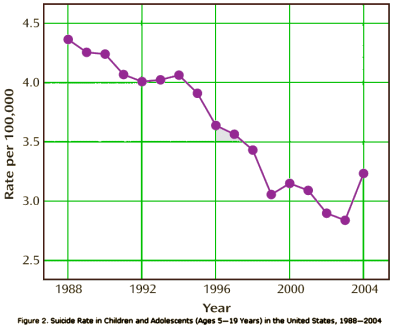
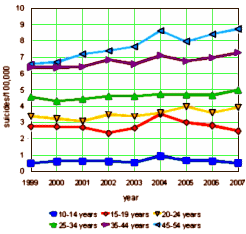
 But I’m done with the science of this article and defer to people with more wisdom and talent on the methods of analysis. I want to talk about something else related – Big Data [see two points…]. It’s all the rage now and deserves our attention. Essentially, it comes from places like Google, Amazon, the NSA. It’s a way of thinking about the huge databases being amassed everywhere. The book is about how people are learning how to query and correlate these huge datasets without worrying so much about missing data and unequal sample sizes. We don’t think about it, but a lot of our science is based on looking at a small sample, then extrapolating to the general population – so we’re super precise and use our statistical tests and our rational brains. Big Data people don’t worry about that so much. They have huge data [like approximating all of it]. And they don’t care if the correlations don’t make sense [as in the most accurate index for following the spread of flu is an algorithm that queries Google searches]. It’s the fact that they correlate that matters. And this study [Changes in antidepressant use by young people and suicidal behavior after FDA warnings and media coverage: quasi-experimental study] is Big Data. They have an impressive dataset:
But I’m done with the science of this article and defer to people with more wisdom and talent on the methods of analysis. I want to talk about something else related – Big Data [see two points…]. It’s all the rage now and deserves our attention. Essentially, it comes from places like Google, Amazon, the NSA. It’s a way of thinking about the huge databases being amassed everywhere. The book is about how people are learning how to query and correlate these huge datasets without worrying so much about missing data and unequal sample sizes. We don’t think about it, but a lot of our science is based on looking at a small sample, then extrapolating to the general population – so we’re super precise and use our statistical tests and our rational brains. Big Data people don’t worry about that so much. They have huge data [like approximating all of it]. And they don’t care if the correlations don’t make sense [as in the most accurate index for following the spread of flu is an algorithm that queries Google searches]. It’s the fact that they correlate that matters. And this study [Changes in antidepressant use by young people and suicidal behavior after FDA warnings and media coverage: quasi-experimental study] is Big Data. They have an impressive dataset: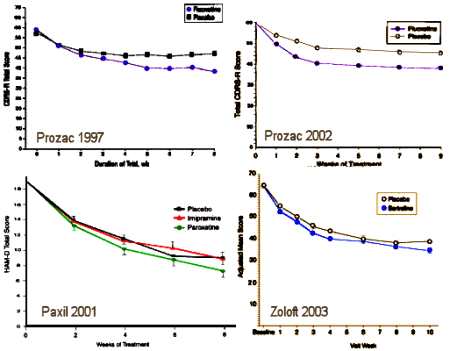
The Clinical Trial era has already confronted us and our patients with the problem of small differences in medication effect and reams of treatment guidelines that may or may not be meaningful. We’d best anticipate that studies like this one are just harbingers of what’s going to happen when these vast datasets gathered by electronic medical records, HMOs, prescriptions, pharmacies, scanners, screenings, etc multiply exponentially in the coming years. I expect some good things will emerge, but the possibilities for confusion, error, and deceit will likely grow in parallel. In psychiatry, we already have studies ongoing like iSpot and EMBARC that hope to pick your antidepressant based on some collection of other measurable parameters [don’t hold your breath]. Add to that the dream of adjusting your medication dose based on your weekly iPhone CAT-D App via a brief chat on the cloud with your tele-psychiatrist. Maybe your Google searches can get in the mix as well [I wish I were exaggerating].

New England Public Radioby Rob SteinJune 18, 2014
… “I think there were a lot of mistakes made in terms of how this risk was communicated to the public, which led a lot of parents to be terrified to have their children on these medications — and they took them off and there was a lot of untreated, serious depression,” says Robert Gibbons, a University of Chicago biostatistician who advised the FDA on the issue…
- Reuters
- Forbes
- USA TODAY
- Washington Post
- CBS News
- Daily Mail
- BBC News
- Toronto Star
- Boston Globe
- FiercePharma
And why we are grateful for your continued writing…
Another campaign for sure. It won’t stop until national governments realize that the field of psychiatry is worked and harvested by big pharma aka big business.
In Stavanger one of the biggest events every year is the november week of
http://www.schizofrenidagene.no – comparable in size to the oil industries’ events, ministers of health present, politicians, beaurocrats, psychiatrists, doctors, hundreds of nurses, international guests,
Patric McGorry is speaking this year, media coverage, publishers, journalists … The program in english is online. They’re still at it with the “attenuated psychosis” business, TIPS for early intervention in psychoses, hardly an echo of the criticism raised abroad.
A tried-and-true ploy in demogoguery: “But what about the children?!”