I don’t know if my musings about the Linux story worked, but what I was trying to talk about was the computer community’s struggles with the secrecy of the commercial developers – a problem similar to ours with Clinical Trials and their sponsors. Watching those computer code struggles happen from the sidelines, things took of when Linux came around and they had a new own platform [operating system]. Linus’s problem with "UI" [user interface] has held them back [see Ted talk – in here’s Linus…], but others are beginning to make it easier to use now. My point was rather than trying to gain access to the systems of others, they came into their own when they had their own system.
For many reasons, I think that something similar is ultimately the only real solution to the problem of industry’s control of drug trial and reportings. RCTs may be appropriate for drug approval purposes, the and FDA usually bases the approval on making the a priori declared primary outcome variables. But they aren’t so appropriate for deciding about actual usage of the drugs, particularly when presented in the journal articles we call experimercials – often distorted by a variety of tricky moves. Medicine is going to have to find some non-commercially driven way to test drugs that will give us reliable ongoing clinical information – our own Open Source platform.
But in the meantime, I’ve been thinking about data transparency – having access to all of the raw data from clinical trials. I certainly think that’s the way it should be. Medicine is almost by definition an open science. The majority of clinical education is apprenticeship, freely given. No secret potions, no wizards allowed. Secret data just doesn’t fit. But the business end of industry isn’t medicine. I frankly doubt that we’ll get access to all the data free and clear any time soon. It’ll probably always long be a fight like it was for us with Paxil Study 329. The marketeers see that data as part of their commodity and hold on to it at any cost. So they’ll stick with their restrictive data sharing meme as long as possible; jump on any legality they can find along the way; play havoc with the EMA’s or anyone else’s data release plan; etc. [and they can afford a lot of havoc!].
-
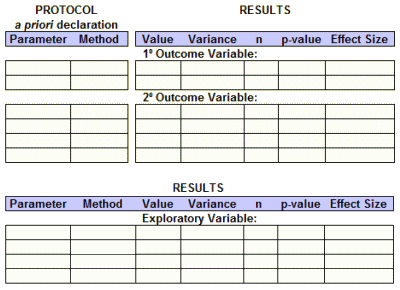
What are the a priori defined primary and secondary outcome variables and how will they be analyzed?
-
What are the results of those specific analyses after the study was completed?
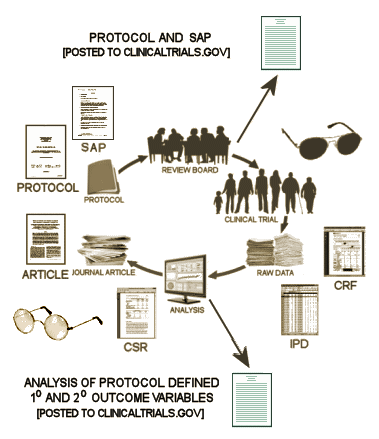
So, whether we have access to the raw data or not, we should be able to fill out this Basic Efficacy Table [or something close] for every Clinical Trial. The reasons we can’t are mixed up with non-compliance and non-enforcement, not non-consensus or non-requirenent:
It would take a single payer with enormous financial clout to force such a change. For example, if a government outside of the US, would refuse to cover the cost of a medication unless all clinical trials relevant to that medication were publicly posted and then actively disseminated. After all, if taxpayer dollars are paying for the medication, and the public is consuming them, then shouldn’t all information on the pills be available?
I think you may be right when you say “Medicine is going to have to find some non-commercially driven way to test drugs that will give us reliable ongoing clinical information – our own Open Source platform.”
I know you transition to “in the meantime” but I really don’t know that we will, at least for the coming decade+, get the things you talk about following that “in the meantime.” I know you are drawn by your own internal muses, but I would be interested in hearing more brainstorming around what could be built. Most especially what could be built without having to retire to be able to participate.