Decline in placebo-controlled trial results suggests new directions for comparative effectiveness research.
by Olfson M and Marcus SC.
Health Affairs. 2013 32[6]:1116-1125.
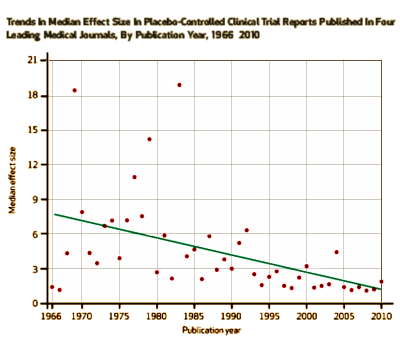
The Affordable Care Act offers strong support for comparative effectiveness research, which entails comparisons among active treatments, to provide the foundation for evidence-based practice. Traditionally, a key form of research into the effectiveness of therapeutic treatments has been placebo-controlled trials, in which a specified treatment is compared to placebo. These trials feature high-contrast comparisons between treatments. Historical trends in placebo-controlled trials have been evaluated to help guide the comparative effectiveness research agenda. We investigated placebo-controlled trials reported in four leading medical journals between 1966 and 2010. We found that there was a significant decline in average effect size or average difference in efficacy [the ability to produce a desired effect] between the active treatment and placebo. On average, recently studied treatments offered only small benefits in efficacy over placebo. A decline in effect sizes in conventional placebo-controlled trials supports an increased emphasis on other avenues of research, including comparative studies on the safety, tolerability, and cost of treatments with established efficacy.
-
National Trends in the Office-Based Treatment of Children, Adolescents, and Adults With Antipsychotics. Archives of General Psychiatry. 2012 69[12]:1247-1256.
-
National Trends in the Antipsychotic Treatment of Psychiatric Outpatients With Anxiety Disorders. American Journal of Psychiatry 2011 168:1057-1065.
-
Proportion Of Antidepressants Prescribed Without A Psychiatric Diagnosis Is Growing. Health Affairs [2011] 30:1434-1442.
-
National trends in the outpatient diagnosis and treatment of bipolar disorder in youth. Archives of General Psychiatry. 2007 Sep;64[9]:1032-1039.
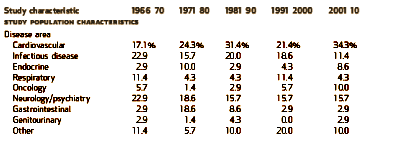
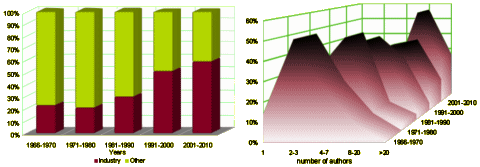
I graphed some of their tabular data to make it easier to see [all were significant]. On the left is the percent of Clinical Trials where PHARMA funding was acknowledged. This figure is confusing as that only became a requirement during the study period [NEJM 1985, JAMA 1989, BMJ 1994, Lancet 1994]. On the right, the number of authors rose from a median of 2-3 to 8-20 over the study period! Who knew?
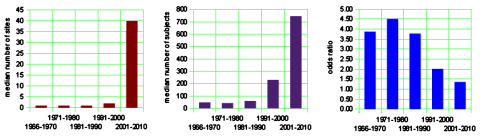
The left graph below shows the median number of sites used in the clinical trials. The trend to multiple sites is a striking phenomenon of the recent past, I presume reflecting the ascendency of of the Clinical Research Organizations. Similarly, in the center the median number of study subjects has soared over the last two decades [chasing significance]. And on the right, another way of showing the falling effect size – the mean odds ratio.
And finally some miscellaneous stats from their tables. In this study the % of non-US studies, studies with insignificant Primary Outcomes, and drop-out rates did not change significantly. Intent-to-treat analysis means all subjects that start the study are included including drop-outs etc [corrected for missing data]. Studies reporting number of subjects screened and ITT analysis increased significantly.
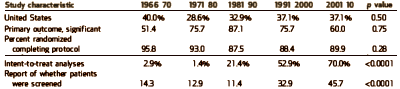
[reformatted]
I obviously liked this study – well-done, timely, well-analyzed. I’m not sure I’m through digesting it, but several things occurred to me. First, my focus has been on the deceit in the psychiatric clinical trial world and I tend to see the problems with clinical trials as localized to psychiatry. This study widens that lens to all of medicine. I was surprised by that. Besides deceit, I’ve also tended to blame the falling effect sizes on the Clinical Research Industry using recruited subjects often in far-away lands with culturally diverse subgroups. So I wouldn’t have expected the same decline in trials of biomarker-confirmed physical diseases. But there it is.
It’s the rare clinical trial article that doesn’t comment on the small effect sizes these days – blaming the placebo effect or other karmic forces. And this paper makes it very clear that they are escalating the number of subjects [requiring multiple sites] to chase significance with smaller effect sizes. But I find it impossible to look at this data and conclude anything except that, on the whole, they’re testing weaker and weaker drugs.
Declining Differences in Response Rates with Antidepressants versus Placebo: A Modest Proposal for Another Contributing Cause.
by Preskorn SH.
Journal of Psychiatric Practice. 2013 19:227-233.
This column discusses declining differences in response rates between sequentially introduced selective serotonin reuptake inhibitors [SSRI] and placebo. Although discussions of this phenomenon in the literature have largely focused on increasing placebo response rates, the author proposes that another factor may be responsible. That factor is an order effect, meaning that response rates have been declining as a function of the number of SSRIs on the market when the next SSRI is in development. The rationale is that the pool of potential clinical trial participants likely to respond to a drug with this mechanism of action [MOA] becomes progressively smaller with the introduction of each new agent with the same MOA, because many patients will already have been treat- ed and responded to an earlier member of the class. This phenomenon is not limited to the SSRIs but generalizes to any class of treatments that shares the same MOA.
So how does this:
http://www.nytimes.com/2013/06/07/business/an-experimental-drugs-bitter-end.html
fit within the narratives being discussed in the comments the past few weeks?
or sample size?
http://www.ncbi.nlm.nih.gov/pubmed/23653079
Helge,
Excellent point…
[see update]
Maybe some of that $100 billion should be directed to understanding the curative factors behind the placebo effect?
The rest of medicine has definitely peddled some bad drugs, some of them causing the problems they were supposed to treat. Fosamax, Actonel and Boniva for osteoporosis caused bone death. Beta blockers caused heart attacks.
Vandia caused heart problems in diabetics, who are at high risk of heart attack. Vioxx caused heart attacks and strokes. Saw an advertisement for a new drug to treat arthritic pain recently. My friend and I started laughing (we have a dark sense of humor) during the list of possible negative effects. It sounded like it was supposed to cause severe illness.
More public money, for more (of the same) research?
It doesn’t sound so “affordable” somehow.
The ‘Not-so Affordable Health Care Act ‘ would have been a more appropriate name for the legislation.
Duane
“Trust us” say the same politicians, researchers, KOLs.
“Are you kidding?” say those of us who’ve been paying attention.
Duane
Does Dr. Preskorn address in his article that if pharmaceutical companies used the old drugs with similar MOAs as active comparators in their trials of new drugs that it would help clarify a lot of what he is bringing up?
Part of why taking Dr. Preskorn’s statements at face value gives me pause:
http://www.neurosciencecme.com/cmea.asp?ID=250
http://www.cmeoutfitters.com/cme_disclosure.asp?ID=250
Neurosciencecme has run stuff like this:
http://www.neurosciencecme.com/email/2008/011508_ckc.htm
Which then links to:
http://www.neurosciencecme.com/cmea.asp?ID=272
http://carlatpsychiatry.blogspot.com/2007/09/author-calls-his-own-cns-spectrums.html
http://carlatpsychiatry.blogspot.com/2007_09_01_archive.html
None of this changes tha it is a clever idea. Some of this may suggest careful vetting of what might be motivating the idea. What corollary conclusions he draws from it.
Harking back to:
http://1boringoldman.com/index.php/2013/03/29/least-squares-mean-patients/
Is this:
http://www.badscience.net/2013/06/badger-badger-badger-badger-cull-badger-badger-badger-trial/
From that post:
“But more importantly, the trial loses what evidence nerds call “external validity”: the ideal perfect intervention, used in the trial, is very different to the boring, cheap, real-world intervention that the trial is being used to justify.
This is a common problem, and the right thing to do next is a new trial, this time in the real world, with no magic. The intervention could be the thing we’re doing, and the outcome could be routinely collected bovine TB data, since that’s the outcome we’re interested in. This gives you answers that matter, on the results you care about, with the intervention you’re going to use.
People worry that research is expensive, and deprives participants of effective interventions. That’s not the case when your intervention and data collection are happening anyway, and when you don’t know if your intervention actually works. Here, though, as in many cases, the missing ingredient is will.”
Also referenced in the post:
http://apps.who.int/rhl/Lancet_365-9453.pdf
It also reminded me of this:
http://davidhealy.org/not-so-bad-pharma/#comment-79092
In particular Dr. Chalmers comments, including:
“4. Cannot provide patient-level answers. As randomised n-of-1 trials are top of the draft of the EBM Group’s evidence hierarchy published several years ago, this is not true. And if you’re referring to using data from groups to provide prediction of treatment effects in individual patients then you should give examples of how you overcome this unavoidable challenge by preferring non-randomised groups to randomized groups as a basis for the guess.”
The evidence hierarchy can be found here:
http://www.cebm.net/mod_product/design/files/CEBM-Levels-of-Evidence-2.1.pdf
I hope that at some point you highlight that Dr. Chalmers, Dr, Goldacre, et al are big proponents of n of 1 trials performed through collaboration of the physician and patient. Not really of large CRO RCTs.