

Posted on Thursday 12 November 2015
I was reading along in Dr. Makari’s Opinion piece in the New York Times when I got to the final paragraphs where he artfully articulated something I’ve been trying to say for a very long time:
New York Times – OpinionBy GEORGE MAKARINOV. 11, 2015…
Unfortunately, Dr. Kane’s study arrives alongside a troubling new reality. His project was made possible by funding from the National Institute of Mental Health before it implemented a controversial requirement: Since 2014, in order to receive the institute’s support, clinical researchers must explicitly focus on a target such as a biomarker or neural circuit. It is hard to imagine how Dr. Kane’s study [or one like it] would get funding today, since it does not do this. In fact, psychiatry at present has yet to adequately identify any specific biomarkers or circuits for its major illnesses.
Critics worry that this new stipulation will limit clinical studies and foster what has been all too familiar in psychiatry — unwarranted speculation aimed at prematurely reducing many layers of intersecting causality to one. If so, the institute will become the latest in a long, unhappy line of those who pressed for a simple solution to the Janus-faced problems of mind-brain illness. In the meantime, Dr. Kane’s study provides pragmatic clinicians with strong new evidence for an old idea: Individuals with mental illness should be fully engaged as beings whose rich psyches and ever-present social worlds are just as real as their brains.
I’ve been hard on Tom Insel and tried to say why every time I write about him, but I don’t ever feel like I get it said. But it’s simple. He thought he owned the NIMH and its directions. Last week in an interview, he blamed the NIMH’s inadequate analytic fire-power for not confirming his nebulous RDoC:
Five years ago, the NIMH launched a big project to transform diagnosis. But did we have the analytical firepower to do that? No. If anybody has it, companies like IBM, Apple or Google do – those kinds of high-powered tech engines…
Clinical Neuroscience, RDoC, Neural Circuits: These are some things he decided would lead us to the promised land, and so he made them preconditions for receiving NIMH grant money! No offense, but the Director of the NIMH is supposed to create an environment where our best and brightest researchers can pursue their ideas. It’s fine to keep them out of the stratosphere and insist that they propose projects that have some general value and realistic goals, but that’s not what Tom Insel did. He essentially told them what things he was interested in having them work on. Is the RDoC something of value? Who knows? Mainly because it doesn’t even exist. And would it transform diagnosis? Who knows? Again, because it doesn’t exist. And about those Neural Circuits, take a look at this earnest resident pretending to talk to a patient [the talk that matters…] about her Neural Circuits [instead of confronting her about her addictive behavior]:
Dr. Insel’s replacement will need to start by de-Inselizing the NIMH, and that’s going to be a big task. He micromanaged everything to follow his agendae. I wonder if it ever occurred to him that the reason that the NIMH didn’t give him what he wanted is that maybe it wasn’t there to find. He may have kept the researchers from spinning off and following some idiosyncratic path, but he did it by forcing them to follow his own idiosyncratic path.
 O! be some other name:
O! be some other name: While there was, indeed, a lot of corruption in the years around the turn of the century, to dismiss it with something tanamount to "but there was a lot of that going around" as if it were a fad or a pesky virus hardly rises to any reasonable medical or academic standard. It’s an argument as lame as "… such policies might restrain innovation and delay translation of basic discoveries to clinical benefit." Medicine arose in ancient history and survived for centuries not based on powerful scientific advances. Those advances are only in their second century. Medicine prevailed because it was among the few professions that was able to adhere to a consistent and enduring ethical stance. A resistance to outside Conflicts of Interest has been an implied element of that ethic throughout our history. Arguments such as those expressed in this JAMA viewpoint article simply have no place in our tradition or our literature. And to have these recent articles actually advocating for conflicted authorship in our two major journals [NEJM:
While there was, indeed, a lot of corruption in the years around the turn of the century, to dismiss it with something tanamount to "but there was a lot of that going around" as if it were a fad or a pesky virus hardly rises to any reasonable medical or academic standard. It’s an argument as lame as "… such policies might restrain innovation and delay translation of basic discoveries to clinical benefit." Medicine arose in ancient history and survived for centuries not based on powerful scientific advances. Those advances are only in their second century. Medicine prevailed because it was among the few professions that was able to adhere to a consistent and enduring ethical stance. A resistance to outside Conflicts of Interest has been an implied element of that ethic throughout our history. Arguments such as those expressed in this JAMA viewpoint article simply have no place in our tradition or our literature. And to have these recent articles actually advocating for conflicted authorship in our two major journals [NEJM:  While I’ve given up political blogging for good, there is a story I followed in the past that may finally be coming to a long awaited resolution. It’s the story of Burma [Myanmar] which is under a military dictatorship backed by the world’s largest standing army. Since my summary in 2007 [
While I’ve given up political blogging for good, there is a story I followed in the past that may finally be coming to a long awaited resolution. It’s the story of Burma [Myanmar] which is under a military dictatorship backed by the world’s largest standing army. Since my summary in 2007 [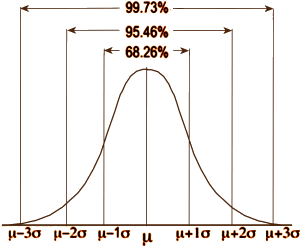 In statistical testing, assumptions abound. For continuous variables, we assume that the data follow a normal distribution, so we can simplify the dataset into just three numbers: the mean [μ], the standard deviation [σ], and the number of subjects [n]. In an RCT, with just those numbers for the placebo group and the drug group, we can calculate the needed probability. In the normal distribution, all the items between two standard deviations on either side of the mean make up 95% of the sample. Values outside those limits make up only 5% of the sample. In doing statistical testing for the difference between two groups [assuming for the moment an equal σ and n], when the probability of the null hypothesis is 0.05 or less [p < 0.05], we feel confident that the groups are significantly different. But that only tells us that the groups are different – not how different.
In statistical testing, assumptions abound. For continuous variables, we assume that the data follow a normal distribution, so we can simplify the dataset into just three numbers: the mean [μ], the standard deviation [σ], and the number of subjects [n]. In an RCT, with just those numbers for the placebo group and the drug group, we can calculate the needed probability. In the normal distribution, all the items between two standard deviations on either side of the mean make up 95% of the sample. Values outside those limits make up only 5% of the sample. In doing statistical testing for the difference between two groups [assuming for the moment an equal σ and n], when the probability of the null hypothesis is 0.05 or less [p < 0.05], we feel confident that the groups are significantly different. But that only tells us that the groups are different – not how different.  In this simple two group example, calculating the p value depends on having the means [μ1 and μ2], the standard deviations [σ1 and σ2], and the two sample sizes [n1 and n2]. And this is about as far as they got in my medical school version of a statistics course in the dark ages called the 60s
In this simple two group example, calculating the p value depends on having the means [μ1 and μ2], the standard deviations [σ1 and σ2], and the two sample sizes [n1 and n2]. And this is about as far as they got in my medical school version of a statistics course in the dark ages called the 60s  [only scratching the surface of the field]. So those of us doing research had to add some other degrees. They do a better teaching job in these modern times [with computers to do the heavy number crunching instead of the calculators that shook the table and sounded like Gatling guns]. And with the increased computer power came much more sophisticated statistical testing allowing the evaluation of many more factors in the models.
[only scratching the surface of the field]. So those of us doing research had to add some other degrees. They do a better teaching job in these modern times [with computers to do the heavy number crunching instead of the calculators that shook the table and sounded like Gatling guns]. And with the increased computer power came much more sophisticated statistical testing allowing the evaluation of many more factors in the models.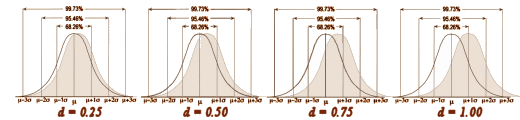
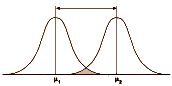 Even a strong Cohen’s d isn’t a huge separation – plenty of overlap still in the picture. So when you’re looking at Effect Sizes, don’t think it looks like the figure on the left [d = 4]. You’re usually still back in the land of sometimes when you’re looking at these Effect Sizes in a Clinical Trial report in a journal article.
Even a strong Cohen’s d isn’t a huge separation – plenty of overlap still in the picture. So when you’re looking at Effect Sizes, don’t think it looks like the figure on the left [d = 4]. You’re usually still back in the land of sometimes when you’re looking at these Effect Sizes in a Clinical Trial report in a journal article. 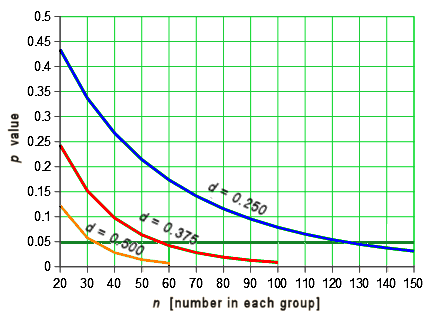

 dramatic decrease in capillary density. That was a significant finding, but hardly the point of the study – an observation along the way. The classic example is the discovery of Penicillin. Alexander Fleming, a veteran of WWI, was involved in looking for antimicrobial agents, having seen so much sepsis in that war. He sure wasn’t studying dirty petri dishes. But when he saw a bacteria-free ring around a mold in a dirty petri dish, he knew what he was looking at – an observation along the way.
dramatic decrease in capillary density. That was a significant finding, but hardly the point of the study – an observation along the way. The classic example is the discovery of Penicillin. Alexander Fleming, a veteran of WWI, was involved in looking for antimicrobial agents, having seen so much sepsis in that war. He sure wasn’t studying dirty petri dishes. But when he saw a bacteria-free ring around a mold in a dirty petri dish, he knew what he was looking at – an observation along the way.![Clinical Neuroscience timeline [2005]](http://1boringoldman.com/images/insel-1.gif "Clinical Neuroscience timeline [2005]")
 It just doesn’t seem to register anymore that this class of articles reporting clinical trials is published in academic journals, but it has no real connection to anything "academic." I’ve referred to the authors highlighted in red as "tickets," as if their function is to certify admission to the journals. I recently suggested facetiously in
It just doesn’t seem to register anymore that this class of articles reporting clinical trials is published in academic journals, but it has no real connection to anything "academic." I’ve referred to the authors highlighted in red as "tickets," as if their function is to certify admission to the journals. I recently suggested facetiously in