

Posted on Friday 11 September 2015
The RIAT Initiative was a bright idea. Rather than simply decrying unpublished or questionable Clinical Trials, it offers the original authors/sponsors the opportunity to set things right. If they decline, the RIAT Team will attempt to do it for them with a republication. Success depends on having access to the raw trial data and on having it accepted by a peer reviewed journal [see “a bold remedy”…]. Both the BMJ and PLoS had responded to the RIAT article by saying they would consider RIAT articles. Paxil Study 329 had certainly been proven "questionable" in the literature and in the courts. And most of the data was already in the public domain thanks to previous legal actions. So a group of us who had independently studied this study assembled to begin working on breathing life into the RIAT concept. Dr. Jon Jureidini and his Healthy Skepticism group in Australia had mounted the original [and many subsequent] challenges to this article. He was joined there by colleagues Melissa Raven and Catalin Tofanaru. Dr. David Healy, well known author and SSRI expert was joined in Wales by Joanna Le Noury. Elia Abi-Jaoude in Toronto and yours truly in the hills of Georgia, USA rounded out the group. I was certainly honored to be included. While all of us have some institutional affiliation, this project was undertaken as an unsupported and unfunded enterprise without connection to any institution. Though my own psychiatric career was primarily as a psychotherapist, in a former incarnation, I was a hard science type with both bench and statistical training. So I gravitated to the efficacy reanalysis, and that’s the part I’ll mention here and in some remarks after the paper is published.
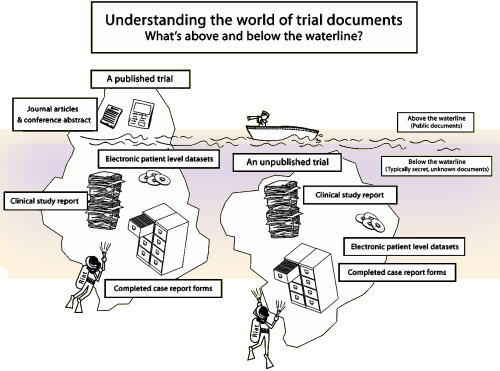
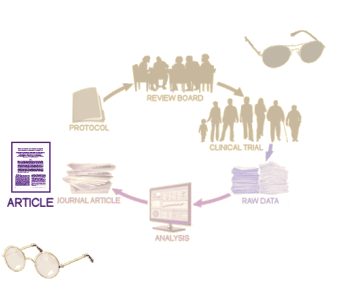
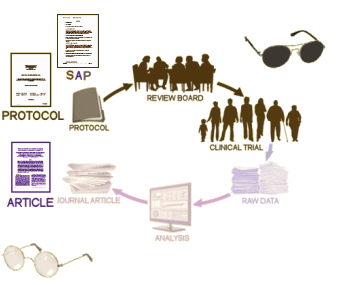
The Full Study Report Acute was a 528 page document that addressed the 8 week acute phase of Paxil Study 329. The actual raw data was in additional Appendices. On the first pass through this document, we considered a number of approaches to presenting the data. In recent years, there has been a move away from the traditional statistical analysis towards also considering the Effect Sizes. Statistics only tell us that groups are different, but nothing about the magnitude of that difference. Effect Sizes approximate the strength of that difference and have found wide acceptance particularly in meta-analyses like those produced by the Cochrane Collaboration. But in the end, we decided that our article was more than simply about Study 329, we wanted it to represent how such a study should be properly presented. And since every Clinical Trial starts with an a priori protocol that outlines how the analysis should proceed, we decided, wherever possible, to follow the original protocol’s directives.
Looking over the protocol, it was comprehensive. We found two things that were awry. First, the comparator group was to take Imipramine, and the dose was too high for adolescents – 1.5 times the dose used in the Paxil trials for adults. That was apparent in the high incidence of side effects in that group in the study. The second thing was a remarkable absence. There was no provision for correcting for multiple variables to avoid false positives. The more variables you look at, the more likely you are to find a significant correlation by chance alone. There are many different correction schemes from the stiff Bonferroni correction to a number of more forgiving schemes. This study had two primary and six secondary efficacy variables. The protocol should have specified some method for correction, but it didn’t even mention the topic. Otherwise, the protocol passed muster. It was written well before the study began and it was clear about the statistical methods to be used on completion to pass judgement on efficacy. One other question came from the protocol, how were we going to deal with missing values. The protocol defined all of the outcome variables in terms of LOCF [last observation carried forward]. In the intervening 14 years, LOCF has largely been replaced by other methods: MMRM [Mixed Model, Repeat Measurements] and Multiple Imputation. We used the protocol directed LOCF method, but at the request of reviewers and editors, we also show the Multiple Imputation analysis for comparison.
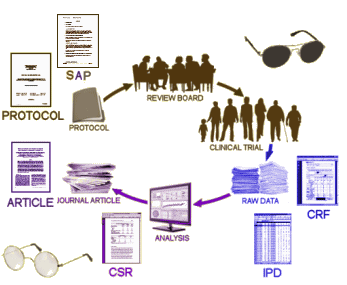
I guess the only other thing to say before the paper is published is that this was quite an undertaking. There were no precedents for any aspect of this effort. I’ve mentioned just a few of the decisions we had to make along the path, but every one of them and many others are the result of a seemingly endless stream of email and drop-box communications that regularly sped around the globe. There’s no part of this paper that doesn’t have the collective input of most of the authors. There were no technicians, statisticians, or support staff involved so we drew our own graphs, built our own tables, ran our own numbers, and checked and revised each others work. As with any new thing, looking back over it, it’s easy to see how it could have been a much more streamlined process. But that’s only apparent looking through a retrospectascope. Somewhere down the line, I hope we’ll have the energy to pass on some of the many things we learned along the way to help future RIATers have an easier passage.
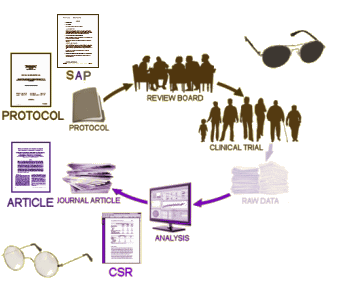

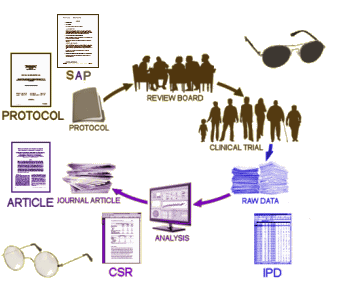
 In the laboratory, you can take two groups of genetically identical animals living under the same conditions and give one group a medication and the other something inert, then compare the results. We humans are much harder. We’re not genetic clones. We live in a wide variety of ways and places. We’re a fickle lot – sometimes we don’t consistently take the medication; sometimes we miss appointments; sometimes we drop out of studies altogether. And then there’s this placebo effect thing. For reasons known and unknown, just being in a study itself often makes us significantly better, a particularly common finding in psychiatric drug trials. Thus any Clinical Trial comes out of the gate with built in variabilities and confounding factors, no matter what is being tested. Then there’s time. Most trials are short compared to the projected drug use. So a Clinical Trial is only a rough starting point at best, picking up on harms and judging efficacies in a closely attended but brief setting – an abnormal setting.
In the laboratory, you can take two groups of genetically identical animals living under the same conditions and give one group a medication and the other something inert, then compare the results. We humans are much harder. We’re not genetic clones. We live in a wide variety of ways and places. We’re a fickle lot – sometimes we don’t consistently take the medication; sometimes we miss appointments; sometimes we drop out of studies altogether. And then there’s this placebo effect thing. For reasons known and unknown, just being in a study itself often makes us significantly better, a particularly common finding in psychiatric drug trials. Thus any Clinical Trial comes out of the gate with built in variabilities and confounding factors, no matter what is being tested. Then there’s time. Most trials are short compared to the projected drug use. So a Clinical Trial is only a rough starting point at best, picking up on harms and judging efficacies in a closely attended but brief setting – an abnormal setting. I’ve had the opportunity to be on a
I’ve had the opportunity to be on a  The video in the last post [
The video in the last post [ But even though I understand and even approve of the embargo, that doesn’t mean that I enjoy waiting for publication to talk about our paper. I’ve been thinking about that Keller et al article for five years now, and actively working on our RIAT paper for two years. So it’s hard to think about much else these last several weeks [as in my recent posts are monotonous, mostly about RCTs]. But I’ll have to admit that the wait has had something of a positive effect in that it has focused my thinking onto an important topic. You guessed it – the topic is embargos – and specifically on the pharmaceutical industry’s embargo on the primary data from their Clinical Trials.
But even though I understand and even approve of the embargo, that doesn’t mean that I enjoy waiting for publication to talk about our paper. I’ve been thinking about that Keller et al article for five years now, and actively working on our RIAT paper for two years. So it’s hard to think about much else these last several weeks [as in my recent posts are monotonous, mostly about RCTs]. But I’ll have to admit that the wait has had something of a positive effect in that it has focused my thinking onto an important topic. You guessed it – the topic is embargos – and specifically on the pharmaceutical industry’s embargo on the primary data from their Clinical Trials.
 And so our article is about more than bringing the data from one Clinical Trial out into the daylight. It’s an example of what can be learned in general from the examination of the raw data when conducted by people who don’t work for the company [that’s us] – who don’t have the kinds of conflicts of interest that are ubiquitous in these Industry funded RCTs [that’s us too]. The goal is, of course, to add our voices to the growing cry to make the actual raw data available for every Clinical Trial…
And so our article is about more than bringing the data from one Clinical Trial out into the daylight. It’s an example of what can be learned in general from the examination of the raw data when conducted by people who don’t work for the company [that’s us] – who don’t have the kinds of conflicts of interest that are ubiquitous in these Industry funded RCTs [that’s us too]. The goal is, of course, to add our voices to the growing cry to make the actual raw data available for every Clinical Trial…



 So I needed a new counter-top Microwave Oven. I moved on to amazon.com and used the "stars" from other shoppers to make my selection. Maybe the American Journal of Psychiatry could institute something like that real soon. It would be easier than making somebody have to think up things to say in an editorial…
So I needed a new counter-top Microwave Oven. I moved on to amazon.com and used the "stars" from other shoppers to make my selection. Maybe the American Journal of Psychiatry could institute something like that real soon. It would be easier than making somebody have to think up things to say in an editorial…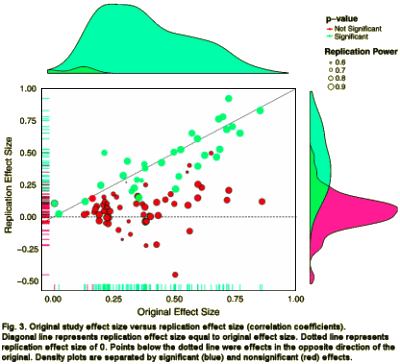
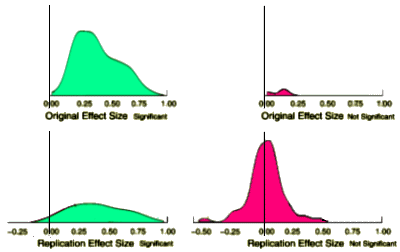
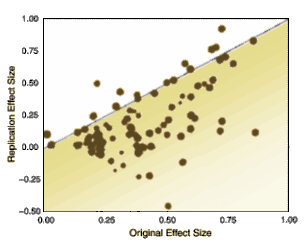
 Well look here. Those two guys from
Well look here. Those two guys from