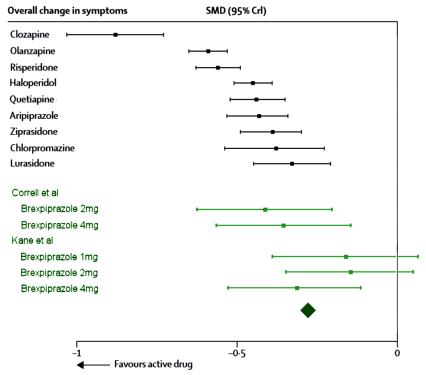
This figure is obviously adapted from the last post [oh well…]. It’s the strength of effect [Standardized Mean Difference AKA Cohen’s d AKA ~Hedges g] of the Atypical Antipsychotics [in black] in the treatment of Schizophrenia with the values for Brexpiperazole added below [in green]. The upper values are from thousands of patients compiled in a meta-analysis and the Brexpiperazole values are from a few hundred in two recent RCTs [see the spice must flow…]. In an earlier version of this figure, I hadn’t put in the 95% Confidence Limits [because I didn’t know how]. The diamond at the bottom is the weighted mean for the Brexpiprazole values [SMD = -0.28].
While the practice of using p·values as a gold standard continues in our psychiatry journals, that’s not the case throughout the scientific world. To make the point for the thousandth time, all a p·value tells you is that two populations differ, but not by how much. Statistical separation can vary from trivial to meaningful, and the p·value doesn’t reveal anything about that variability. So the American Psychological Association recommends that the Effect Size with its 95% Confidence Intervals be universally reported [and many of their journals won’t publish articles that don’t include them]. The Effect Size not only adds the dimension of the magnitude of an effect, in many cases, it can be used for comparisons between studies.
Though the Effect Size adds a quantitative dimension to the RCT analysis over the qualitative p·value, it’s no gold standard either. Note the width of the 95% Confidence Intervals in the Brexpiprazole data. Is that because these are individual RCTs rather than pooled studies with much larger groups? Is it because these are CRO-run studies spread over [too] many sites [60 each!]? We don’t know that. All we really know is that it sure is a wide interval, apparent also in the standard deviation values [σ]:
| BREXPIPRAZOLE Trials in Schizophrenia
|
|||||||||
| STUDY | DRUG | MEAN | SEM | σ | n | p | d | lower | upper |
| Correll et al | placebo | -12.01 | 1.60 | 21.35 | 178 | – | – | – | – |
| 0.25mg | -14.90 | 2.23 | 20.80 | 87 | 0.3 | 0.14 | -0.120 | 0.393 | |
| 2mg | -20.73 | 1.55 | 20.80 | 180 | <0.0001 | 0.41 | 0.204 | 0.623 | |
| 4mg | -19.65 | 1.54 | 20.55 | 178 | 0.0006 | 0.36 | 0.155 | 0.574 | |
| Kane et al | placebo | -13.53 | 1.52 | 20.39 | 180 | – | – | – | – |
| 1mg | -16.90 | 1.86 | 20.12 | 117 | 0.1588 | 0.166 | -0.067 | 0.399 | |
| 2mg | -16.61 | 1.49 | 19.93 | 179 | 0.1488 | 0.153 | -0.054 | 0.360 | |
| 4mg | -20.00 | 1.48 | 13.45 | 181 | 0.0022 | 0.321 | 0.113 | 0.529 | |
A thing of beauty, this little table. It doesn’t answer all the questions, but it gives you all the information you need to think about things in an informed way. The Effect Size [d] values and their 95% Confidence Intervals are a decided plus. In a way, these two articles are exemplary. The papers themselves tell you that it is an industry funded, ghost written article. All the information in the table is either in the paper or easily calculated [in red]. Add the information on clinicaltrials.gov, and you are in a position to make informed decisions about what these two studies have to say about the efficacy of Brezpiprazole. And now to the point of this post. These papers represent progress. While it’s not Data Transparency proper, it’s close enough for everyday work. But this is the exception to the rule, to be able to make that table with a minimal expenditure of energy.
These two papers are not available on line, and the abstracts in PubMed don’t have enough information to construct the table. So you have to have access to the papers. If your retirement hobby is trying to evaluate these RCTs of psychiatric drugs, you already know that in the majority of papers, it isn’t possible to make that table this easily, if at all. Though all you really need is the MEAN, the number of subjects, and either the SEM [Standard Error of the Mean] or the Standard Deviation for each group – and you’re good to go. But invariably, they’re not available. The results are frequently reported in some other way, and one gets the feeling that it’s by design – a bit of subterfuge. But whether that conclusion is an acquired paranoia on my part or the truth doesn’t matter. What matters is that you can’t do what’s needed to understand the efficacy results and to compare them with other studies.

 This is the stuff of premature hair loss and nervous twitches in the brave souls who do meta-analyses. And they’ve responded by finding ways to gather the needed information to produce tables like this one. Their methodology is buried in big thick books like the Cochrane Handbook for Systemic Reviews of Interventions or expensive software like the Comprehensive Meta-Analysis software. This is hardly the stuff for your basic hobby blogger like me. Fortunately, there are all kinds of formulas and Internet calculators scattered around that allow one to get the job done. So the next one of these in the land of sometimes… posts will likely be a short catalog of these tools [for we mortals] for exhuming the information that should’ve been provided by the authors/writers in the first place. Boring? yes. Necessary? also yes. The alternative is tantamount to drinking the Kool-ade.
This is the stuff of premature hair loss and nervous twitches in the brave souls who do meta-analyses. And they’ve responded by finding ways to gather the needed information to produce tables like this one. Their methodology is buried in big thick books like the Cochrane Handbook for Systemic Reviews of Interventions or expensive software like the Comprehensive Meta-Analysis software. This is hardly the stuff for your basic hobby blogger like me. Fortunately, there are all kinds of formulas and Internet calculators scattered around that allow one to get the job done. So the next one of these in the land of sometimes… posts will likely be a short catalog of these tools [for we mortals] for exhuming the information that should’ve been provided by the authors/writers in the first place. Boring? yes. Necessary? also yes. The alternative is tantamount to drinking the Kool-ade.
Not Boring
Many thanks
Don
A paper sponsor takes a hit if they allows data to be presented in a way that better supports construction of such a table. Right now it seems they take a bigger hit than for obscuring the data, because other companies can use such constructions against them like a club.
The psychiatric community’s “response” to your BMJ paper (and the accompanying commentaries) illustrates how much “we” care about such obscuring (and worse) on the part of academic leaders.
On a practical note, if you have the time to comment on some of the texts out there (as well as some of the online tools) that would be very helpful. E.g., don’t know how well “How to Read a Paper” by Greenhalgh works as a primer for those of less experienced in such matters.