Finding the actual data from Study 329 posted in early August was invigorating [
a movement…]. I could finally have a go at looking at the things I’d only been able to guess about before. For example, I knew that the authors of that Study had abandoned a primary outcome parameter [
HAM-D either ≤50% baseline or HAM-D ≤8 @ 8 weeks] and introduced another [
HAM-D ≤8 @ 8 weeks]. It must’ve been because it looked better, but I didn’t know why. With the data available, it was easy to see:
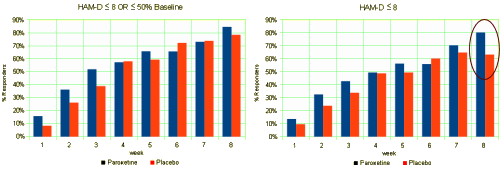
The 8 week value with their newly constructed parameter [circled far right] was an outlier and made the difference look a whole lot more like what they wanted to see [wanted us to see]. And there were numerous other examples of what Neuroskeptic aptly calls the dark arts. I’ve kind of been on a data transparency high since I found that data. Not that I wasn’t there before, but now it seems more like an imperative. Thinking about Neuroskeptic’s analysis in the last post, falsifying or fabricating data is outright fraud, a crime. But the mis-use of the tools of science or other artifice in constructing an article is what he called questionable practices, all of which come after the fact and would be easily detected if we had the facts in hand. So the solution is posting the raw data and looking at the article itself as what it really is, an editorial shell around it [as opposed to hiding the data behind the article]:


I don’t know if that would be necessary for every scientific paper, but history tells us that, for sure, it is the right thing to do for clinical trials in profit yielding psychopharmacologic drugs. We’ve had decades of the alternative and it has come to no good. I do have a question about the clinicaltrials.gov results database being up to the task of true data transparency. A few weeks back, I started to look into it…
… but decided to table it until the doldrums of winter when I would have more time to think. It’s one of those situations where the devil’s in the details, and I was having trouble getting into a details frame of mind. Something about the way that database is constructed bothers me. I’d hate for us to spend the time insisting on something, only to find that it had some holes in it. More later.
Speaking of things about Clinical Trials, I was pointed to one recently that had some unusual features – actually it was two clinical trials of the same thing, six week of Geodon in Bipolar I Depression. It was an industry study through and through:
This study was funded by Pfizer Inc. Editorial support was provided by Annie Neild, PhD, of PAREXEL and was funded by Pfizer Inc. AUTHOR DISCLOSURE INFORMATION: Drs Lombardo, Kolluri, Kremer, and Yang are employees of Pfizer Inc. Dr Sachs, owned stock in Concordant Rater Systems, Inc, and is now an employee of United BioSource Corporation. He has received grants for clinical research from Abbott, GlaxoSmithKline, Janssen, and Pfizer. Dr Sachs is on advisory boards for Abbott, Bristol-Myers Squibb, Dainippon Sumitomo Pharma, GlaxoSmithKline, Janssen, Eli Lilly, Merck, Otsuka, Pfizer, and Repligen.
Two 6-Week, Randomized, Double-Blind, Placebo-Controlled Studies of Ziprasidone in Outpatients With Bipolar I Depression Did Baseline Characteristics Impact Trial Outcome? by Ilise Lombardo, MD,* Gary Sachs, MD,Þþ Sheela Kolluri, PhD,* Charlotte Kremer, MD,* and Ruoyong Yang, PhD* Journal of Clinical Psychopharmacology. 2012 32:470-478.
Two randomized, double-blind, placebo-controlled, 6-week studies comparing ziprasidone versus placebo for treatment of bipolar depression [BPD] failed to meet their primary study objectives, indicating that either ziprasidone is ineffective in the treatment of BPD or the study failed.
Adult outpatients with bipolar I depression with 17-item Hamilton Rating Scale for Depression total score more than 20 at screening and baseline received either ziprasidone 40 to 80 mg/d, 120 to 160 mg/d, or placebo [study 1], or ziprasidone 40 to 160 mg/d or placebo [study 2]. Primary efficacy measure in both studies was change from baseline in Montgomery-Åsberg Depression Rating Scale total scores at week 6 [end of the study]. Mixed-model repeated-measures methodology was used to analyze the primary efficacy measure in both studies. Secondary efficacy measures in both studies included Hamilton Rating Scale for Depression total score and Clinical Global Impression-Improvement score. Post hoc analyses were conducted for both studies to examine potential reasons for study failure. In both, ziprasidone treatment groups failed to separate statistically from placebo for change from baseline Montgomery-Åsberg Depression Rating Scale score at week 6. Response rates were 49%, 53%, and 46% for placebo, ziprasidone 40 to 80 mg/d, and ziprasidone 120 to 160 mg/d, respectively [study 1], and 51% and 53% for placebo and ziprasidone 40 to 160 mg/d, respectively [study 2].
Ziprasidone 40 to 160 mg/d did not show superiority over placebo at week 6 in the treatment of BPD. Post hoc analyses revealed serious inconsistencies in subject rating that may have limited the ability to detect a difference between drug and placebo response. Rating reliability warrants further investigation to improve clinical trial methodology in psychiatry.
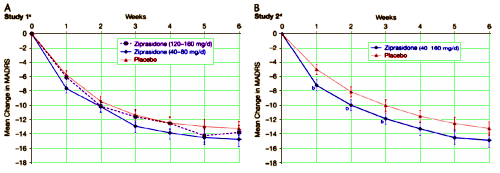
These were CRO [Clinical Research Organization] studies [
PAREXEL] started in 2005 & 2006 [Clinical Trials
NCT00141271 &
NCT00282464]. CROs obviously profit from speedy [and positive] results. Since there’s such a strong placebo effect, they need large numbers [486 & 369], and the only way to get them is to use large networks of multiple sites [56/70 & 45/48]. Needless to say, these are
recruited subjects, and in such studies, dropout rates are high [Placebo 33% & 31%, Geodon 40% & 38%]. In an "
effort to mitigate against the baseline inflation," they used the
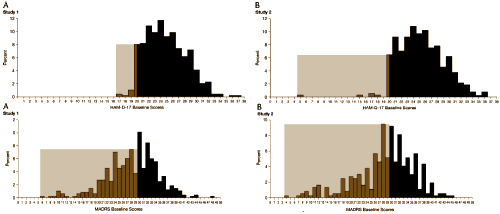
Hamilton Rating Scale for Depression [HAM-D] for screening and acceptance and the
Montgomery-Åsberg Depression Rating Scale [MADRS] for serial efficacy analysis. Baseline inflation is when eager raters maximize symptoms to include subjects in these lucrative trials. Both studies were solid busts by any measure [they’re called "negative studies" because there was no active comparator].
At this point, my expected response would be to rant about the Clinical Research Organization studies, but I’m not going to do that because this time, they put the data to good use and gave us a peek behind the screen. First, one might think that these two commonly used depression rating scales might give similar results. In fact there’s even a conversion formula:
MADRS = 1.43 × HAM-D + 0.87
So they compared the HAM-D qualifying scores to the initial MADRS scores [I know the text is too small to read, but you won’t need it – there’s nothing subtle here]:
Studies 1 & 2 are side-by-side. On top, the HAM-D scores at screening – below, the initial MADRS scores. They’re scaled to be equivalent by the formula. Not even close! They didn’t mitigate baseline inflation, they proved it! [they reanalyzed using only MADRS confirmed subjects and it was negative too]. One more for the road – the placebo response rates at different sites for the two studies side by side:
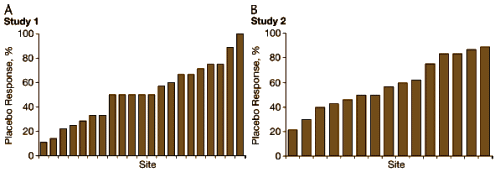
They did some other
post hoc analyses and the results were equally awful. No matter where they looked, they found uninterpretable correlations. We owe
PAREXEL and
Pfizer a debt of gratitude for publishing this article that was such a stinging indictment of this kind of clinical trial – the kind they rely on. I’m going to reserve comments on Clinical Research Organization trials in general for another post, and stick to the topic of data transparency, because this study points to a major reason that we need to insist on it. Had they not done this
post hoc analysis for us, we couldn’t have known about the baseline inflation, the non-correlation between MADRS and HAM-D scales, or the large placebo effect and its variation across sites. With the raw data, we could’ve known those things and much more. As I said
before, "
… the only reason I can think of for keeping the raw data from clinical trials secret is to make distortion possible"…
[errors corrected 8AM 10/05/2012]
Mickey,
You corrected your initial version of this note to make clear that these are ‘negative studies” and not “failed studies” but in the paper you quoted the phrase …or the study failed” sounds like a bit of spin and if that’s what it is shouldn’t it be pointed out?
It sounds like the way in which, in describing clinical cases, some psychopharm mavins will use the expression “The patient failed a trial of X drug” placing the onus on the patient instead of saying “X drug failed to help the patient.”
Yeah, it’s easy to see why I got it wrong.
But your point about the onus being on the patient rather than the drug is excellent. It’s like the patient has “treatment resistant depression” rather than the drugs don’t work a lot of the time.
“Treatment-resistant depression” !!!!! Calling Monty Python!!!!!