Generally, folk heros are from the past like John Henry and represent some laudable principle – like man versus machine. Back in the upside-down years of the 60s, Arlo Guthrie had a shot with his endless comical antiwar song, Alice’s Restaurant. The premise, however, was dead serious. When enough people get behind a needed change, that’s when things finally happen. We’ve seen some of that with Data Transparency and distorted Clinical Trial reports alread [though not near enough].
Generally, folk heros are from the past like John Henry and represent some laudable principle – like man versus machine. Back in the upside-down years of the 60s, Arlo Guthrie had a shot with his endless comical antiwar song, Alice’s Restaurant. The premise, however, was dead serious. When enough people get behind a needed change, that’s when things finally happen. We’ve seen some of that with Data Transparency and distorted Clinical Trial reports alread [though not near enough].
I happen to agree with Arlo that the hard work of righting a wrong is in keeping it on the front burner [as in the Civil Rights Movement, Women’s Rights, Gay Rights], and the distortion of the scientific record by corruptly reported Clinical Trials is a wrong of sufficient magnitude to dog until it’s past history. While Psychiatry lead the pack there for a while, it’s a problem throughout medicine that needs our full attention – and I personally have come to believe that without Data Transparency, it will never happen. One of the major frustrations with these journal articles is that you can’t get at the data itself to evaluate things yourself, at least that’s been my major frustration. Even if you have an academic connection that allows you access to the articles themselves rather than just the abstracts, they often omit key parameters that would allow you to get under the carefully crafted rhetoric even with the crude tools described in the first two john henry’s hammer posts to see what’s going on.
I’ve been monotonously preoccupied with the most recent arrival on the psychiatric scene,
Brexpiprazole [
Rexulti®] acting on the principle of early detection – if there’s something awry, the sooner it’s exposed the better. Looking at their Schizophrenia data, the papers are ghost-written industry productions sure enough, but they give us enough information to do a reasonable elm-tree mechanic vetting. It’s a middle-weight antipsychotic, a clone of the blockbuster
Aripiprazole [
Abilifyi®]. But when I look at the two articles introducing it as an
adjunct for augmenting antidepressants in treatment resistant depression [for which it also has FDA Approval!], it’s a different story. First off, there’s the sleight of hand Protocol infraction [see
income switching…] that I’m going to reject with no more comment and look only at the original Protocol [they call it the
efficacy population]. But when I go looking for the summary data on the primary outcome variable [change in MADRS score at 6 weeks], here’s all I find:
"Mean change in MADRS total score for the efficacy population also showed improvement for brexpiprazole 3 mg versus placebo (−1.52; 95% CI, −2.92 to −0.13; P = .0327) but did not reach the level of statistical significance required for multiple comparisons according to the prespecified statistical analysis. The mean improvement for brexpiprazole 1 mg versus placebo was less than that for 3 mg (−1.19; 95% CI, −2.58 to 0.20; P = .0925)."
from Efficacy and safety of adjunctive brexpiprazole 2 mg in major depressive disorder: a phase 3, randomized, placebo-controlled study in patients with inadequate response to antidepressants.
"Similar results were seen for brexpiprazole versus placebo in the efficacy population (LS mean = −8.27 vs −5.15; LS mean difference =−3.12 [95% CI, −4.70 to −1.54], P = .0001)."
They give us all the summary data we could ever want on all of their secondary outcome variables, but not the primary outcome variable in either article [a μ or so with the "good article," but no SEM or σ]. So I went to the FDA Medical Report, hoping that since they approved the drug for this indication, they would give us more. No such luck. Maybe I missed something [and I’d appreciate someone else taking a look], but I ended up with a table that was barely populated and a mighty lonely spreadsheet:
BREXPIPRAZOLE Trials Augmenting Treatment Resistant Depression
|
| STUDY |
DRUG |
MEAN |
SEM |
σ |
n |
p |
d |
lower |
upper |
Thase
et al |
placebo |
– |
– |
–
|
218 |
– |
–
|
–
|
– |
| 1mg |
|
|
|
225 |
0.0925 |
|
|
|
| 3mg |
|
|
|
226
|
0.0327 |
|
|
|
Thase
et al |
placebo |
-8.27
|
– |
–
|
191 |
–
|
– |
– |
–
|
| 2mg |
-5.15
|
|
|
187 |
0.0001
|
|
|
|
Instead, they give us the difference between the means…
(μ1–μ2)
and the 95% confidence limits – the formula for that is:
CI[95%]=(μ1–μ2)±1.96×√((σ1²÷n1)+(σ2²÷n2))
There’s just no way I can figure to deconstruct those values, work it backwards, and end up with the summary data [even though I know they had it and used it to generate something I didn’t particularly want]. In the two articles, they give us four tables of summary data for secondary outcome variables – two with their jury-rigged numbers in the articles and two with the real numbers in the supplements, but for their declared primary outcome variables, slim pickings.
Admittedly, some claim that reporting the difference in the MEANs is an Effect Size and don’t convert it to a Standardized MEAN Difference [Cohen’s d], but I’m not in that particular some [and they aren’t either, since the same people didn’t do that in their Schizophrenia articles from the same company with the same ghost-writing firm – even reporting the Cohen’s d in their best showing article]. So what’s a fellow who’s trying to write a guide for other elm-tree vetters going to do in this situation? Is John Henry’s Hammer dead in the water? I say where there’s a will, there’s a way. Stay tuned.
When I read Spielmans et al’s meta-analysis of the augmentation with Atypical Antipsychotics in treatment resistant depression [see the extra mile…], I ran across these lines:
"The quality of data reporting varied across studies. For continuous outcomes, effect sizes were computed from means and standard deviations when possible. When these were not provided, effect sizes were computed based on means and p-values, or p-values only."
7.7.7.2 Obtaining standard errors from confidence intervals and P values: absolute (difference) measures
… The first step is to obtain the Z value corresponding to the reported P value from a table of the standard normal distribution. A standard error may then be calculated as
SE = intervention effect estimate/Z.
As an example, suppose a conference abstract presents an estimate of a risk difference of 0.03 (P = 0.008). The Z value that corresponds to a P value of 0.008 is Z = 2.652. This can be obtained from a table of the standard normal distribution or a computer (for example, by entering =abs(normsinv(0.008/2) into any cell in a Microsoft Excel spreadsheet). The standard error of the risk difference is obtained by dividing the risk difference (0.03) by the Z value (2.652), which gives 0.011.
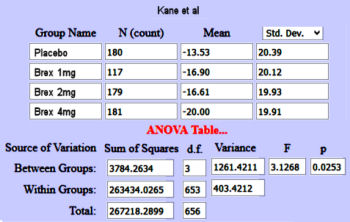
Still a little heady for John Henry’s hammer, but promising. The Z value is the area under the normal distribution curve used to compute p-values. But while looking around about the Z value, I ran across the Mother Lode – Psychometrica, a German web site tailor made for my purposes. It has an Internet Calculator that takes the Z value and the sample size [n1+n2] and out comes Cohen’s d. And on top of that, I found another Internet Calculator that produces a Z Score from a p-value [remember, you have to divide the p-value by 2 first!] requiring neither tables nor spreadsheet visits. So, armed with my two new calculators, I decided to try it out first on something where I had arrived at Cohen’s d and the CI[95%] by other means. So, back to the Brexpiprazole in Schizophrenia Trials [truncated with the new stuff in green]. You’ll note that I’m using my p-values rather than the ones in the articles because one of theirs appears to be in error [Kane 1mg], and that I changed the sign on Cohen’s d and the CI[95%] :
BREXPIPRAZOLE Trials in Schizophrenia
|
| STUDY |
DRUG |
n |
p |
d |
lower |
upper |
Z |
n1+n2 |
new d |
Correll
et al |
placebo |
178 |
– |
– |
– |
– |
– |
– |
– |
| 0.25mg |
87 |
0.2976 |
0.137 |
-0.120 |
0.393 |
1.0146 |
265 |
0.128 |
| 2mg |
180 |
0.0001 |
0.414 |
0.204 |
0.623 |
3.8906 |
358 |
0.420 |
| 4mg |
178 |
0.0007 |
0.365 |
0.155 |
0.574 |
3.3896 |
356 |
0.365 |
Kane
et al |
placebo |
180 |
– |
– |
– |
– |
– |
– |
– |
| 1mg |
117 |
0.1629 |
0.166 |
-0.067 |
0.399 |
1.3951 |
297 |
0.162 |
| 2mg |
179 |
0.1488 |
0.153 |
-0.054 |
0.360 |
1.4438 |
359 |
0.153 |
| 4mg |
181 |
0.0025 |
0.321 |
0.113 |
0.529 |
3.0233 |
361 |
0.322 |

 I agree with John Henry and Arlo! Those numbers are close enough for elm tree work in my book! I had no clue if this would pan out, so my hat’s off to the Calculator makers. Why do you divide by two? For that matter, how does it work? I don’t know those answers yet. Magic?
I agree with John Henry and Arlo! Those numbers are close enough for elm tree work in my book! I had no clue if this would pan out, so my hat’s off to the Calculator makers. Why do you divide by two? For that matter, how does it work? I don’t know those answers yet. Magic?
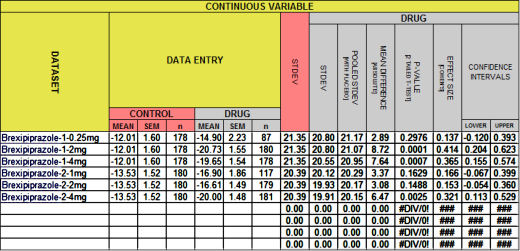
So moving right along – What about that other dataset where I didn’t know the the Effect Sizes? [The CI[95%] are from the formula in john henry’s hammer: continuous variables I…. This one’s also truncated with the new stuff in green]:
BREXPIPRAZOLE Trials Augmenting Treatment Resistant Depression
|
| STUDY |
DRUG |
n |
p |
Z |
n1+n2 |
d |
lower |
upper |
Thase
et al |
placebo |
218 |
– |
– |
– |
– |
– |
– |
| 1mg |
225 |
0.0925 |
1.6824 |
443 |
0.160 |
-0.027 |
0.347 |
| 3mg |
226 |
0.0327 |
2.1357 |
444 |
0.204 |
0.017 |
0.390 |
Thase
et al |
placebo |
191 |
– |
– |
– |
– |
– |
– |
| 2mg |
187 |
0.0001 |
3.8906 |
378 |
0.409 |
0.205 |
0.613 |
I doubt if anyone is much surprised that the 3mg dose in that first study had a trivial Cohen’s d – right near inert. Why else would they make it so hard to generate it? But when you take away the Protocol sleight of hand and look at the Effect Size of 0.204, that p-value of 0.0327 doesn’t look very impressive at all. And that’s the point. Of course p and d are still just numbers. But adding the Effect Size [d] to the mix definitely deepens our understanding of the reported values well beyond the p-value. If the authors don’t give an Effect Size, and the editors don’t insist on an Effect Size, we need to be able to easily generate it ourselves.
As much as I’d like to rale at the FDA for that Augmentation Approval, or run down the internal workings of these last two Internet Calculators, my goal was to provide a way to vet studies by adding the Effect Sizes even if they withheld the summary values – and I think I’ve either done it or am close enough to take a breather. My mathematico-statistico-html-table-formatting libido is all used up for today…


 s flying in Korea into scrapbooks, and had drills at school about how to hide from thermonuclear annihilation by getting under our desks. And except for things like the Cuban Missile Crisis, these things just faded into the background of life. And then there were signs of a thawing. In 1968, Alexander Dubçek became the President of Czechoslovakia and began to reform their Communist government, the Prague Spring. He allowed foreign travel, and my brother-in-law and his wife booked a trip, arriving a day or so before the Tanks from the Warsaw Pact invaded and put an end to Dubçek’s nonsense. After several nail-biting days holed up in a hotel, they were able to get on a train out of there.
s flying in Korea into scrapbooks, and had drills at school about how to hide from thermonuclear annihilation by getting under our desks. And except for things like the Cuban Missile Crisis, these things just faded into the background of life. And then there were signs of a thawing. In 1968, Alexander Dubçek became the President of Czechoslovakia and began to reform their Communist government, the Prague Spring. He allowed foreign travel, and my brother-in-law and his wife booked a trip, arriving a day or so before the Tanks from the Warsaw Pact invaded and put an end to Dubçek’s nonsense. After several nail-biting days holed up in a hotel, they were able to get on a train out of there. I don’t recall ever giving much thought to how the Iron Curtain actually worked. I’d seen the Berlin Wall and gone through Checkpoint Charlie for an afternoon. I guess I thought of it as something like that. And then one night, something remarkable happened. I had left Emory for private practice and our group [and secretary] were grossly dissatisfied with the only billing system that was available – a pegboard affair used by medical doctors. There wasn’t any billing software for a small session-based office like ours, so I set out to write some. I wrote it in dBase-III+, the language of the day. It came out better than I could’ve imagined, but to run it you had to have dBase-III+ on your [DOS] computer and it was agonizingly slow. Then a company called Clipper released a compiler that turned dBase-III+ programs into standalones that were as fast as the wind by the standards of the day. With that addition, I was beginning to sell my little program to people in the area, and I often spent my evenings on a message board Clipper had on Compuserve working out the inevitable bugs in such things. This was before the Internet. Well, the Internet was there, but Tim Berners-Lee hadn’t come up with his html language, there was no browser or world wide web, and Al Gore hadn’t invented the Information Highway [by alerting us that it was already there].
I don’t recall ever giving much thought to how the Iron Curtain actually worked. I’d seen the Berlin Wall and gone through Checkpoint Charlie for an afternoon. I guess I thought of it as something like that. And then one night, something remarkable happened. I had left Emory for private practice and our group [and secretary] were grossly dissatisfied with the only billing system that was available – a pegboard affair used by medical doctors. There wasn’t any billing software for a small session-based office like ours, so I set out to write some. I wrote it in dBase-III+, the language of the day. It came out better than I could’ve imagined, but to run it you had to have dBase-III+ on your [DOS] computer and it was agonizingly slow. Then a company called Clipper released a compiler that turned dBase-III+ programs into standalones that were as fast as the wind by the standards of the day. With that addition, I was beginning to sell my little program to people in the area, and I often spent my evenings on a message board Clipper had on Compuserve working out the inevitable bugs in such things. This was before the Internet. Well, the Internet was there, but Tim Berners-Lee hadn’t come up with his html language, there was no browser or world wide web, and Al Gore hadn’t invented the Information Highway [by alerting us that it was already there]. The streets were full of people. The Tanks were rolling. He thought maybe he saw Boris Yeltsin with the crowd. I yelled downstairs for my wife to turn on CNN. They didn’t know as much as I did reading this guy’s green screen messages [which went on all night]. That unrest in Moscow spread like a wildfire throughout the USSR and the rest is history. Down came the Iron Curtain.
The streets were full of people. The Tanks were rolling. He thought maybe he saw Boris Yeltsin with the crowd. I yelled downstairs for my wife to turn on CNN. They didn’t know as much as I did reading this guy’s green screen messages [which went on all night]. That unrest in Moscow spread like a wildfire throughout the USSR and the rest is history. Down came the Iron Curtain. If you haven’t figured out the analogy I’m about to make, wipe the sleepy dust out of your eyes and think about the pharmaceutical industry’s hold on the raw clinical trial data that’s the everyday topic here and elsewhere. It’s more than just an analogy, it’s a direct application out of Stalin’s playbook for holding onto his power. By taking advantage of the low efficacy standard for FDA Approval of a drug and publishing "uncheckable" articles in the medical literature, the companies can turn a weak statistical proof of a drug’s [perhaps trivial] effect into a campaign worth billions.
If you haven’t figured out the analogy I’m about to make, wipe the sleepy dust out of your eyes and think about the pharmaceutical industry’s hold on the raw clinical trial data that’s the everyday topic here and elsewhere. It’s more than just an analogy, it’s a direct application out of Stalin’s playbook for holding onto his power. By taking advantage of the low efficacy standard for FDA Approval of a drug and publishing "uncheckable" articles in the medical literature, the companies can turn a weak statistical proof of a drug’s [perhaps trivial] effect into a campaign worth billions.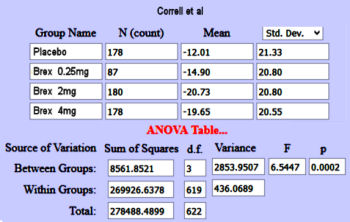

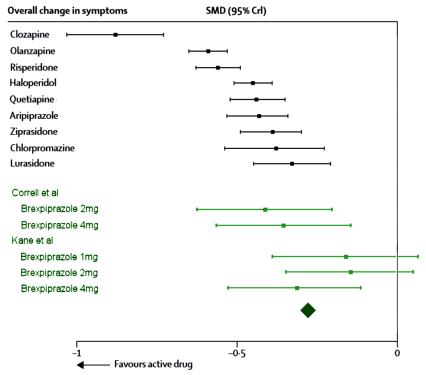

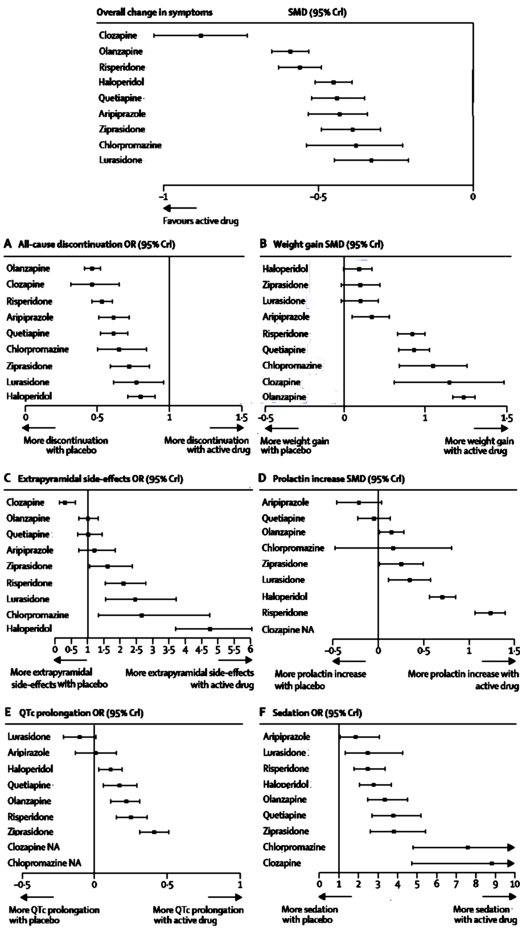
 This is the stuff of premature hair loss and nervous twitches in the brave souls who do meta-analyses. And they’ve responded by finding ways to gather the needed information to produce tables like this one. Their methodology is buried in big thick books like the
This is the stuff of premature hair loss and nervous twitches in the brave souls who do meta-analyses. And they’ve responded by finding ways to gather the needed information to produce tables like this one. Their methodology is buried in big thick books like the