by Matthew J. Press, M.D., Ryan Howe, Ph.D., Michael Schoenbaum, Ph.D., Sean Cavanaugh, M.P.H., Ann Marshall, M.S.P.H., Lindsey Baldwin, M.S., and Patrick H. Conway, M.D.
New England Journal of Medicine. December 14, 2016
DOI: 10.1056/NEJMp1614134
For example, under CoCM, if a 72-year-old man with hypertension and diabetes presents to his primary care clinician feeling sad and anxious, the primary care team [primary care clinician and behavioral health care manager] would conduct an initial clinical assessment using validated rating scales. If the patient has a behavioral health condition [e.g., depression] and is amenable to treatment, the primary care team and the patient would jointly develop an initial care plan, which might include pharmacotherapy, psychotherapy, or other indicated treatments. The care manager would follow up with the patient proactively and systematically [using a registry] to assess treatment adherence, tolerability, and clinical response [again using validated rating scales] and might provide brief evidence-based psychosocial interventions such as behavioral activation [which focuses on helping people with mood disorders to engage in beneficial activities and behavior] or motivational interviewing. In addition, the primary care team would regularly review the patient’s care plan and status with the psychiatric consultant and would maintain or adjust treatment, including referral to behavioral health specialty care as needed.
This paragraph is from an article about how the Centers for Medicare and Medicaid Services [CMS] intends to pay the psychiatrists involved in Collaborative [AKA Integrated] Care [but that isn’t why it’s here]. It has gotten to be something of a hobby of mine to scan these articles as they come around, not that I intend to be involved with the "Psychiatric Collaborative Care Model [CoCM], an approach to behavioral health integration [BHI] that has been shown to be effective in several dozen randomized, controlled trials." What intrigues me is the language used to write them – a bizarre kind of new·speak. I highlighted what I’m talking about in red in the quoted paragraph. Here’s an example of what I’m talking about:
"an initial clinical assessment using validated rating scales. If the patient has a behavioral health condition [e.g., depression] and …"
First off, notice that the rating scales determine whether or not the patient has something wrong. So while the developers of the various rating scales have generally said that they’re not for making a diagnosis, it looks like that’s how they’re being used here. Whoops! Technically, it’s not a diagnosis. It’s a behavioral health condition. That is certainly some kind of new·speak, but it’s not what I’m focused on right this minute. I’m talking about the phrase validated rating scales. We’re accustomed to hearing about validated rating scales when we talk about Clinical Trials, but not running into it in case narratives. Another example:
"[again using validated rating scales] and might provide brief evidence-based psychosocial interventions such as…"
A lot of new·speak in this one, but it’s the evidence-based psychosocial interventions that I’m referring to [I’ll get to brief in a minute]. I haven’t given this an enormous piece of real estate in my head, but so far, this is my tentative lexicon of new·speak categories:
-
adjectives saying that something is evidence-based [meaning positive clinical trials]: validated rating scales, evidence-based psychosocial interventions, evidence based psychotherapy, indicated treatments, guideline approved this and that, etc. The gist of things is that only group-certified interventions are valid…
-
traditional language is de-psychiatrized and de-medicalized: behavioral health care manager, behavioral health condition, rating scales, behavioral health specialty. behavioral activation.
-
strict control, limiting choices and duration of anything: [now we get to brief] – particularly any face to face contact with psychiatrists.
-
adverbs implying contientiousness and industry: proactively and systematically [using a registry]
That’s just off the cuff. With thought, the themes and motives of new·speak will undoubtedly become clearer. Just a few other comments. It’s an odd way to talk no matter what the reason. It sounds a bit like the overinclusive stilted language sometimes heard in chronic Schizophrenia. We get the point that they want everything to be evidence-based [RCT certified], so why append it to every noun? We also get the point that they want psychiatry and psychiatrists out of the picture except to review and to sign off on the cases.
 Just a couple of observations. In every example, the cases are universally lite – unlikely reaching anyone’s standards for mental illness proper. I didn’t really know what behavioral activation and motivational interviewing were. I watched a few youtube videos and looked at several trials of the latter [and there have been many] with widely varying results. They’re behavior modification interview techniques. But the main thing I took away from thinking about this hadn’t occurred to me before. In a way, I’ve already done this myself for over thirty years. I did it in the clinic where I’ve been working for the last eight. And when I was on the faculty, I did it somewhere in some affiliated facility on most days. The med students, or residents, or staff saw the patients and presented them. Sometimes I said "fine." Sometimes we talked about the case. And sometimes I saw the patient myself. I expect most psychiatrists have done this kind of thing at some point in their career for years. But I’m absolutely sure I wouldn’t do this one.
Just a couple of observations. In every example, the cases are universally lite – unlikely reaching anyone’s standards for mental illness proper. I didn’t really know what behavioral activation and motivational interviewing were. I watched a few youtube videos and looked at several trials of the latter [and there have been many] with widely varying results. They’re behavior modification interview techniques. But the main thing I took away from thinking about this hadn’t occurred to me before. In a way, I’ve already done this myself for over thirty years. I did it in the clinic where I’ve been working for the last eight. And when I was on the faculty, I did it somewhere in some affiliated facility on most days. The med students, or residents, or staff saw the patients and presented them. Sometimes I said "fine." Sometimes we talked about the case. And sometimes I saw the patient myself. I expect most psychiatrists have done this kind of thing at some point in their career for years. But I’m absolutely sure I wouldn’t do this one.
The secret to being able to supervise other clinicians in a situation like the one described here isn’t some encyclopedic knowledge of medications, or diagnoses. It’s in being able to get to know how to read the clinician you’re supervising. Early on, I expect I saw most cases a given resident presented. But as I got to know them, I learned when I could trust what I was hearing, versus when something wasn’t right. One almost never knows what’s out of whack from such a presentation, just that you hear yourself saying, "Let’s go take a look." It’s a skill that comes with experience and a lot of it. Of course, the best trainees say, "I don’t know what’s going on with this case. Would you "take a look"? But others don’t know, and so [1] you "take a look" and then [2] try to help them figure out why they were off track, what they missed.
So I guess I know the reason I’m absolutely sure I wouldn’t do this one. That whole system being described up there is designed to keep me out of the room the patient’s in. They don’t need me to help them with behavioral activation and motivational interviewing. They know how to do that certainly better than I. And most of the time, the Primary Care Docs don’t need me to pick an antidepressant. One learns that kind of thing quickly. What they need is someone who has spent a lifetime around suicidal and psychotic patients; who has actually seen most of those unusual medical cases that masquerade as mental illness that most doctors only heard about in medical school; someone who has missed a few diagnoses along the way and knows the dire consequences, is acutely aware when something smells funny. And in this proposed Integrative system, I’m not the one who gets to say, "I need to see this person." Usually, I’m hearing about the case from a care coordinator who may be giving me second-hand information. And even with stable outpatients who aren’t getting better, I wouldn’t have much of a clue how to get the case on track without either seeing the patient, or making sure they’re being seen by someone who really knows the ropes and doesn’t speak new·speak.
Note: When I started writing this post, it wasn’t at all clear to me where I was headed. It’s been that way every time I run across a Collaborative Care article or reference. My reaction has been visceral. It wasn’t until somewhere around that lightbulb up there that I finally could put some words to my reaction. Reading the various versions of Collaborative Care, I always feel the same. But now I can at least make sense of why I respond so negatively. In the system as proposed, I can’t do my job – the actual job assigned to me. I can’t be in charge of saying "Let’s go take a look." And if I can’t do that, there’s really no reason for me to be there in the first place.
Another Note: What’s funny is that a little before the lightbulb, I thought I was finally getting a handle on the why of my reaction. But It was something entirely different from how the post ended, and it’s worth saying in its own right, but it wasn’t "It." So now I guess I’ll have to write yet another post to explain that other reason I react so negatively to these Collaborative Care articles…





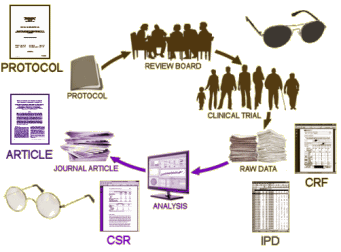
 So what does this have to do with the New England Journal of Medicine, and editor Jeffrey Drazen, and Data Transparency versus Data Sharing, and a bully pulpit? A lot – some mentioned in this series from in April 2016.
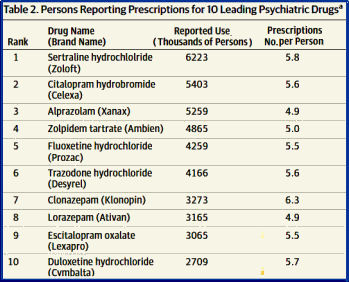
So what does this have to do with the New England Journal of Medicine, and editor Jeffrey Drazen, and Data Transparency versus Data Sharing, and a bully pulpit? A lot – some mentioned in this series from in April 2016. 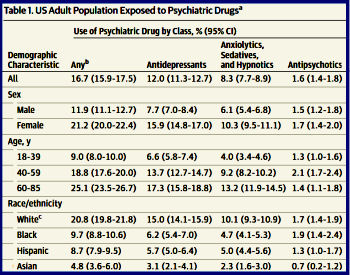

 One encounters patients who appear to live their lives in the domain of the passive voice. Things just happen in the world. Things happen to them [usually bad or disappointing things], but there’s no agent causing them. And invariably, they leave out their own participation in the things that happen. This was once known as the Fate Neurosis. While it may keep them from blaming others, or keep them from shouldering blame themselves, it’s part of a long-suffering view of life that has a sticky persistence that maintains their dysphoria [and often drives their therapists and acquaintances to distraction]. One of the goals of their psychotherapy is to help them see their own part in making things happen, even if it’s negative – to help them see a world in which they are actors rather than victims of obscure forces like fate, destiny, or bad luck. Whodunit? is of major importance in understanding anything that happens to these people [often times theydunit].
One encounters patients who appear to live their lives in the domain of the passive voice. Things just happen in the world. Things happen to them [usually bad or disappointing things], but there’s no agent causing them. And invariably, they leave out their own participation in the things that happen. This was once known as the Fate Neurosis. While it may keep them from blaming others, or keep them from shouldering blame themselves, it’s part of a long-suffering view of life that has a sticky persistence that maintains their dysphoria [and often drives their therapists and acquaintances to distraction]. One of the goals of their psychotherapy is to help them see their own part in making things happen, even if it’s negative – to help them see a world in which they are actors rather than victims of obscure forces like fate, destiny, or bad luck. Whodunit? is of major importance in understanding anything that happens to these people [often times theydunit].  Instead of chasing instances where various biases have colored the reported results after the fact, we could face the reality that distortion and non-compliance are the the expected response. The a priori protocol and declared outcome variables are unlikely to be available a priori. So we could say that no trial can begin until the outcome variables are posted in the registration section on ClinicalTrials.gov. Why not? They’re already available from the Institutional Review Board submission. Similarly, we could say no FDA review of an NDA will be initiated until the Results Database is publicly available filled out on ClinicalTrials.gov for all submitted trials. Why not? They’re being submitted to the FDA so they’re available. Why not submit them to the rest of us?
Instead of chasing instances where various biases have colored the reported results after the fact, we could face the reality that distortion and non-compliance are the the expected response. The a priori protocol and declared outcome variables are unlikely to be available a priori. So we could say that no trial can begin until the outcome variables are posted in the registration section on ClinicalTrials.gov. Why not? They’re already available from the Institutional Review Board submission. Similarly, we could say no FDA review of an NDA will be initiated until the Results Database is publicly available filled out on ClinicalTrials.gov for all submitted trials. Why not? They’re being submitted to the FDA so they’re available. Why not submit them to the rest of us?