An Internal Medicine residency in a charity hospital in Memphis Tennessee in the 1960s was an encounter with Hypertension [High Blood Pressure] of the first kind. The patient population was weighted towards African Americans and we served not only the urban poor of Memphis, but also the rural areas of West Tennessee, Eastern Arkansas, and the Northern Mississippi Delta. If you wanted to learn about Hypertensive Disease, it was the place to be. Besides the ethnic demographic, there was another factor. Not to far from the hospital, there was a huge supermarket that served the same region that was open 24 hours of every day. The dried bean section was stacked floor to ceiling with 25# sacks of White Beans, Pintos, and Black-Eyed Peas. The produce department was mostly greens – Collards, Mustards, Turnip Greens. In the Old South, social status was determined by what part of the pig you ate ["High on the Hog"], and that tradition was apparent at the meat counter: a few hams, butts, and shoulders in a small section at the end, but mostly every other part of a pig, all salt cured – Tails, Feet, Ears, Knuckles, Hocks, Fatback, all thickly encrusted with salt [that you could taste just standing next to the cases]. It was the flavoring for those beans ‘n greens. So it wasn’t just ethnicity working on the Blood Pressure…
-
Malignant Hypertension: The patients would arrive in the ER delirious or in coma with outrageous blood pressure readings. They would have retinal hemorrhages and other vascular eye signs. Kidney function would be compromised. A "stroke" was eminent if it hadn’t happened already. It was a medical emergency, and at the time, the drug of choice was parenteral Reserpine, which did the job. The easiest transition was to oral Reserpine, but the problem was that some fraction of the patients developed a profound melancholic depression [one of the phenomena that lead to the "catecholamine hypothesis" of depression]. So we used the other available drugs of the time – all with plenty of side effects as part of the package.
-
Hypertensive Cardiovascular Disease: These patients were more common. They showed up in the clinics and ER with congestive heart failure of varying intensity: swollen legs, enlarged livers, shortness of breath, sleeping sitting up – with enlarged hearts and Left Ventricular Hypertrophy on EKG [big muscular hearts]. The symptoms cleared with lowering the blood pressure, but they usually got digitalis and diuretics as well.
-
Hypertension: Back then, Hypertension [asymptomatic] was defined as a Diastolic Blood Pressure consistently over 100 mmHg. And there was plenty enough of that around to treat where I was.
My next way station was an Air Force Hospital in the UK – a couple of bases populated with a very different, predomiantly Caucasian group [also younger][also no supermarket like the one in Memphis]. I never saw a case of Malignant Hypertension and not many with Hypertensive Cardiovascular Disease. It was around that time that Treatment Guidelines were beginning to come from the various specialty organizations. The American Heart Association came out with new guidelines for the treatment of High Blood Pressure, and lowered the definition to a Diastolic of 90 mmHg. I didn’t like it. The drugs made people impotent, feel bad. I gave them BP Cuffs to take home. That cured a lot of > 90 mmHg cases ["white coat" syndrome]. I preached weight loss and against salt before tasting. That cured even more. I got a wide BP cuff for fat arms. That was a winner too. I just didn’t feel right treating only a number – making people sick [but I felt guilty when I didn’t]. After that, I was back in Atlanta at a Charity Hospital similar to the one in Memphis training in Psychiatry. When a delirious patient got triaged to the psych floor, the first thing I did was a BP and rolled the Malignant Hypertension cases back downstairs myself to make sure they were seen quickly. Later, when I ran the psych ER, I convinced the medical ER to do a BP before triag on obtunded patients.
And then I forgot about it. Psychotherapist types aren’t in the BP business. And then I got old, and all my friends [and my wife] were on something for BP. Hers was easy. A home BP cuff cured her [70s and 80s]. One day, I thought seriously about it. I was tired of feeling guilty for insisting on hard evidence before following the guidelines [now 140/90, with a Diastolic BP 80-89 as borderline or pre-hypertension]. But what I realized is that there were several things about this that were important. First, I just didn’t believe it. I read all the long term studies, but I wasn’t impressed. Second, I was a treat-the-sick doctor, not a healthy-lifestyle doctor. Had I stayed in Internal Medicine, I guess I would’ve hired me a healthy-lifestyle nurse practitioner to specialize in seeing to that side of things. It just wasn’t in me to spend a lot of time keeping up with the gajillion guidelines that now pour out of our t.v. sets and journals, and I’m not sure I believed what I read a lot of the time anyway. My point is not about your BP meds, or my rebellious streak, it’s about the limits of population studies, statistics, and the relief I felt reading this article:
New York Times
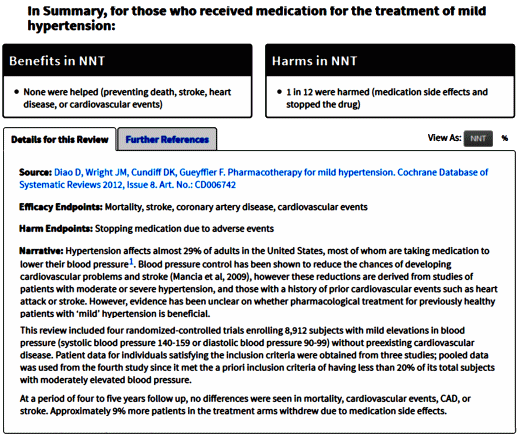
4 heart attacks are not prevented. When 2,000 People Take a Daily Aspirin for Two Years: 1 Heart Attack is Prevented. People at risk for a first heart attack are often recommended to take aspirin daily to prevent it. Only a very few will actually see this benefit and there’s no way to know in advance who.
By Austin Frakt and Aaron E. Carroll
JAN. 26, 2015
In his State of the Union address last week, President Obama encouraged the development of “precision medicine,” which would tailor treatments based on individuals’ genetics or physiology. This is an effort to improve medical care’s effectiveness, which might cause some to wonder: Don’t we already have effective drugs and treatments? In truth, medical care is often far less effective than most believe. Just because you took some medicine for an illness and became well again, it doesn’t necessarily mean that the treatment provided the cure.
This fundamental lesson is conveyed by a metric known as the number needed to treat, or N.N.T. Developed in the 1980s, the N.N.T. tells us how many people must be treated for one person to derive benefit. An N.N.T. of one would mean every person treated improves and every person not treated fails to, which is how we tend to think most therapies work. What may surprise you is that N.N.T.s are often much higher than one. Double- and even triple-digit N.N.T.s are common.
Consider aspirin for heart attack prevention. Based upon both modifiable risk factors like cholesterol level and smoking, and factors that are beyond one’s control, like family history and age, it is possible to calculate the chance that a person will have a first heart attack in the next 10 years. The American Heart Association recommends that people who have more than a 10 percent chance take a daily aspirin to avoid that heart attack.
How effective is aspirin for that aim? According to clinical trials, if about 2,000 people follow these guidelines over a two-year period, one additional first heart attack will be prevented. That doesn’t mean the 1,999 other people have heart attacks. The fact is, on average about 3.6 of them would have a first heart attack regardless of whether they took the aspirin. Even more important, 1,995.4 people would never have a heart attack whether or not they took aspirin. Only one person is actually affected by aspirin. If he takes it, the number of people who remain heart attack-free rises to 1996.4. If he doesn’t, the number remains 1995.4. But for 1,999 of the 2,000 people, aspirin doesn’t make any difference at all.
Of course, nobody knows if they’re the lucky one for whom aspirin is helpful. So, if aspirin is cheap and doesn’t cause much harm, it might be worth taking, even if the chances of benefit are small. But this already reflects a trade-off we rarely consider rationally. [And many treatments do cause harm. There is a complementary metric known as the number needed to harm, or N.N.H., which says that if that number of people are treated, one additional person will have a specific negative outcome. For some treatments, N.N.T. can be higher than the number needed to harm, indicating more people are harmed than successfully treated.]
Not all N.N.T.s are as high as aspirin’s for heart attacks, but many are higher than you might think.
A website developed by David Newman, a director of clinical research at Icahn School of Medicine at Mount Sinai hospital, and Dr. Graham Walker, an assistant clinical professor at the University of California, San Francisco, has become
a clearinghouse of N.N.T. data, amassed from clinical trials…
It wasn’t pleasure in confirmation I felt. It was relief. I guess I felt like I was supposed to believe the AHA guidelines and was conflicted that I didn’t. Was I just adverse to giving those make-you-sick meds? Wanting to be a nice guy? So I felt genuine relief that my persona wasn’t in front of my doctoring in this case.
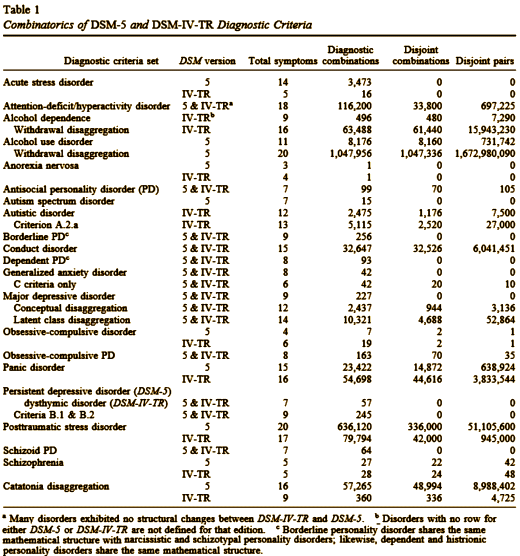
The article is about the simplest of all statistics. If there’s a Clinical Trial where 40% respond to placebo and 50% respond to the drug, then the NNT = 1 ÷ (0.50 – 0.40) = 10. That literally means "you have to treat 10 cases to get 1 responder." Actually, 5 would respond, but only 1 would be because of the treatment. The other 4 were going to respond anyway. What could be simpler? And what could be more telling? The NNT is one of a family of measures of the Strength of the Effect of a treatment [see an anatomy of a deceit 3…].
I’m a Stats-Savvy type, but I never heard of these Strength of Effect measurements until I started to look at RCTs a few years ago and a mentor pointed me to them. In a modern world, an RCT that doesn’t report a Strength of Effect index right there next to the p value is suspect of hiding something. This is a must-read article!
COI Statement: My healthy-lifestyle spouse has been out of town for a week and a half. For supper tonight, I had a NY Strip Steak, and there’s a Crock-Pot on the counter with navy beans, onions, and liberal rashers of salty bacon for tomorrow. Culture is hard to transcend!


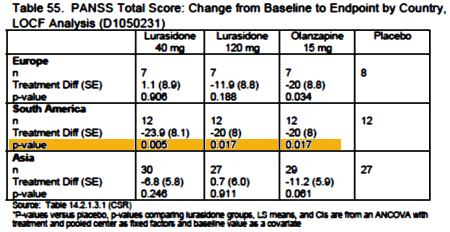
 I didn’t give Latuda® much thought after that. I had noticed in their signature before-and-after ads that Latuda® apparently moves the part from one side of the head to the other like a mirror. So when one of those ads popped up, I always noticed. But otherwise, Latuda® was off my radar. And then it was February 2014, and I looked at the American Journal of Psychiatry and there were two articles about Latuda® Clinical Trials in the same issue and there was an editorial about it. You guessed it, a Bipolar Disorder indication. Then, I wrote [from or both…]:
I didn’t give Latuda® much thought after that. I had noticed in their signature before-and-after ads that Latuda® apparently moves the part from one side of the head to the other like a mirror. So when one of those ads popped up, I always noticed. But otherwise, Latuda® was off my radar. And then it was February 2014, and I looked at the American Journal of Psychiatry and there were two articles about Latuda® Clinical Trials in the same issue and there was an editorial about it. You guessed it, a Bipolar Disorder indication. Then, I wrote [from or both…]: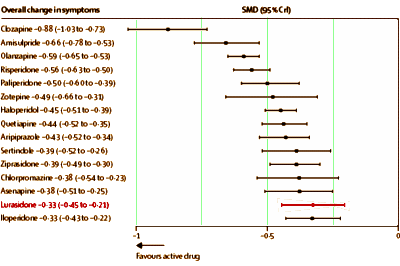
 A growing body of research demonstrates that individuals diagnosed with major depressive disorder (MDD) are characterized by shortened telomere length, which has been posited to underlie the association between depression and increased instances of medical illness. The temporal nature of the relation between MDD and shortened telomere length, however, is not clear. Importantly, both MDD and telomere length have been associated independently with high levels of stress, implicating dysregulation of the hypothalamic-pituitary-adrenal (HPA) axis and anomalous levels of cortisol secretion in this relation. Despite these associations, no study has assessed telomere length or its relation with HPA-axis activity in individuals at risk for depression, before the onset of disorder. In the present study, we assessed cortisol levels in response to a laboratory stressor and telomere length in 97 healthy young daughters of mothers either with recurrent episodes of depression (i.e., daughters at familial risk for depression) or with no history of psychopathology. We found that daughters of depressed mothers had shorter telomeres than did daughters of never-depressed mothers and, further, that shorter telomeres were associated with greater cortisol reactivity to stress. This study is the first to demonstrate that children at familial risk of developing MDD are characterized by accelerated biological aging, operationalized as shortened telomere length, before they had experienced an onset of depression; this may predispose them to develop not only MDD but also other age-related medical illnesses. It is critical, therefore, that we attempt to identify and distinguish genetic and environmental mechanisms that contribute to telomere shortening.
A growing body of research demonstrates that individuals diagnosed with major depressive disorder (MDD) are characterized by shortened telomere length, which has been posited to underlie the association between depression and increased instances of medical illness. The temporal nature of the relation between MDD and shortened telomere length, however, is not clear. Importantly, both MDD and telomere length have been associated independently with high levels of stress, implicating dysregulation of the hypothalamic-pituitary-adrenal (HPA) axis and anomalous levels of cortisol secretion in this relation. Despite these associations, no study has assessed telomere length or its relation with HPA-axis activity in individuals at risk for depression, before the onset of disorder. In the present study, we assessed cortisol levels in response to a laboratory stressor and telomere length in 97 healthy young daughters of mothers either with recurrent episodes of depression (i.e., daughters at familial risk for depression) or with no history of psychopathology. We found that daughters of depressed mothers had shorter telomeres than did daughters of never-depressed mothers and, further, that shorter telomeres were associated with greater cortisol reactivity to stress. This study is the first to demonstrate that children at familial risk of developing MDD are characterized by accelerated biological aging, operationalized as shortened telomere length, before they had experienced an onset of depression; this may predispose them to develop not only MDD but also other age-related medical illnesses. It is critical, therefore, that we attempt to identify and distinguish genetic and environmental mechanisms that contribute to telomere shortening.

 n the days when those ancients first
n the days when those ancients first  uman disagreement before warring people end up shooting at each other. And somewhere along this path, there was a new class in the study of logic called logical fallacies – situations where logical arguments are chronically distorted or misused.
uman disagreement before warring people end up shooting at each other. And somewhere along this path, there was a new class in the study of logic called logical fallacies – situations where logical arguments are chronically distorted or misused. another strong reason we need for Data Transparency to include access to the raw data from those studies we’ve been reading about in our journals all these years. At least in our specialty, having independent teams re-evaluating that information is an important piece of our path to learning what we needed to know in the first place about the ins and outs of medical science [but didn’t]. We drank the Kool-Ade…
another strong reason we need for Data Transparency to include access to the raw data from those studies we’ve been reading about in our journals all these years. At least in our specialty, having independent teams re-evaluating that information is an important piece of our path to learning what we needed to know in the first place about the ins and outs of medical science [but didn’t]. We drank the Kool-Ade…



 Who among us doesn’t have personal memories of early experimentation with embellishments or outright lies? or dealt with the experimentation of our children? or recall disillusioning encounters with friends or colleagues once exposed? And it’s the unusual case of someone in psychotherapy who doesn’t get around to shamefully confessed secrets of such things. Here are Stapel’s comments on his step over the line, quoted by
Who among us doesn’t have personal memories of early experimentation with embellishments or outright lies? or dealt with the experimentation of our children? or recall disillusioning encounters with friends or colleagues once exposed? And it’s the unusual case of someone in psychotherapy who doesn’t get around to shamefully confessed secrets of such things. Here are Stapel’s comments on his step over the line, quoted by  Any modern discussion of Moral Development usually has that word development in it, because morality is not something that just comes with the package. We acquire it along the way. And the terms used to describe it [Superego, Conscience, Moral Compass, Jiminy Cricket] imply it’s an attachment, rather than an integral component. Stapel‘s description of someone standing behind me, is pretty common. Many describe this moral agency as t
Any modern discussion of Moral Development usually has that word development in it, because morality is not something that just comes with the package. We acquire it along the way. And the terms used to describe it [Superego, Conscience, Moral Compass, Jiminy Cricket] imply it’s an attachment, rather than an integral component. Stapel‘s description of someone standing behind me, is pretty common. Many describe this moral agency as t he personified part of the mind [as we acquire it from other people and it’s experienced as a presence]. My point is that we all know people whose morality depends on whether someone is looking or not – it hasn’t become an internalized part of the mind, but remains dependent on an outside monitor like it is in parts of childhood. In a later vignette, also quoted by
he personified part of the mind [as we acquire it from other people and it’s experienced as a presence]. My point is that we all know people whose morality depends on whether someone is looking or not – it hasn’t become an internalized part of the mind, but remains dependent on an outside monitor like it is in parts of childhood. In a later vignette, also quoted by